Ciao e benvenuto alla edizione #44 della EV SEO newsletter, nella quale ho raccolto le novità e i contenuti SEO più interessanti (o almeno quelli che ho trovato tra i tanti che ho letto) delle ultime due settimane.
L’annuncio di BERT, fatto proprio quando avrei voluto pubblicare la newsletter, mi ha spinto ad approfondire la questione ed eccoci qua, con le “2 settimane” di attesa tra una newsletter e l’altra che sono diventate quattro. Porta pazienza: spero che l’attesa sia stata bilanciata dalla qualità di quanto scritto. Per altro da una delle sezioni di questa newsletter è di fatto diventata, durante la sua scrittura, la bozza di un nuovo articolo per il blog del quale però non vorrei ancora svelarti l’argomento! Detto ciò, avendoti già fatto aspettare abbastanza, ti auguro una buona lettura.
Parliamo di BERT, ma parliamone davvero
Da quanto ti dico che l’obiettivo di Google, dopo aver raggiunto un livello (almeno per loro) soddisfacente di efficienza nella lotta allo spam, è quello di comprendere, giudicare e rispondere come fosse un umano le query degli utenti? Da anni ormai.
Anche per questo non stento a credere a quanto dichiarato (e da me parafrasato) a Fortune dal vice presidente di Google Search Pandu Nayak:
La comprensione del linguaggio è la chiave di tutto ciò che stiamo facendo in ambito Search. BERT è il più grande e importante cambiamento positivo che abbiamo avuto negli ultimi 5 anni
BERT, acronimo di Bidirectional Encoder Representations from Transformers, è un modello di rappresentazione del linguaggio presentato già lo scorso anno da alcuni ricercatori di Google e che è entrato a far parte del sistema della Google Search in lingua inglese (trovi il comunicato ufficiale qui). La grande novità di BERT, mi pare di capire leggendo il whitepaper originale, è che questo transformer (termine non riferito agli AutoBot, purtroppo, ma piuttosto al nome del tipo di modello di Natural Language Processing che studia le relazioni tra tutte le parole di una frase e non le analizza solo in serie) in fase di pre-training analizza il contesto delle parole in un testo in modo bidirezionale, non limitandosi quindi a “leggere” e confrontare in un singolo senso, ad esempio da sinistra verso destra, come fanno altri modelli utilizzati per lo stesso scopo.
Purtroppo, visto che sono essenzialmente un asino, non ho le capacità per capire a fondo la spiegazione “matematica” di questa tecnologia ma posso intuire quello che potrà fare per Google e soprattutto posso comunque leggere e comprendere che, oltre a battere ogni record in diversi test sulla comprensione del linguaggio naturale, in uno specifico test chiamato SWAG, dove la valutazione si basa su 113mila test a scelta multipla dove bisogna completare una frase, il modello BERT ha battuto un essere umano nell’accuratezza delle risposte e quindi della comprensione linguistica (nota: l’essere umano ha risposto a un sample di 100 frasi e non tutte e 113mila). Una tecnologia pazzesca!
Parlando dell’applicazione del nostro nuovo amico BERT in ambito Google Search penso che i cosiddetti “Quality Update” che abbiamo visto negli ultimi 2/3 anni fossero, in un qualche modo, un test drive di tecnologie simili, se non i genitori (o i nonni) di BERT stesso: così com’è stato per Penguin e Panda, penso sia partito come un sistema che necessitava di un refresh manuale di alcune sue parti per funzionare, con il risultato di impattare “ad ondate” le SERP fino a quando, come fu proprio per Panda e Penguin, gli ingegneri di Google non sono riusciti a sopperire a questa “dipendenza” dai refresh manuali, arrivando ad essere in grado di essere semplicemente sempre attivi sul motore di ricerca.
Ricordiamoci che BERT, così come gli ultimi “core update”, lavora a livello di query studiando non tanto i siti che popolano le SERP (quelli Google li conosce già meglio di quanto credi) quanto i desideri e le aspettative di chi ha digitato una particolare query. I modelli pre-trained come BERT, come dice il paper stesso, sono in grado, a livello di frasi, di “dedurre e parafrasare, cercando di predire le relazioni tra frasi analizzandole olisticamente”, “abilità” del sistema che trovo esaltanti, quasi sconvolgenti, soprattutto quando penso che verranno applicate in tempo reale su miliardi di query ogni giorno. Gli esempi riportati sono incredibili:
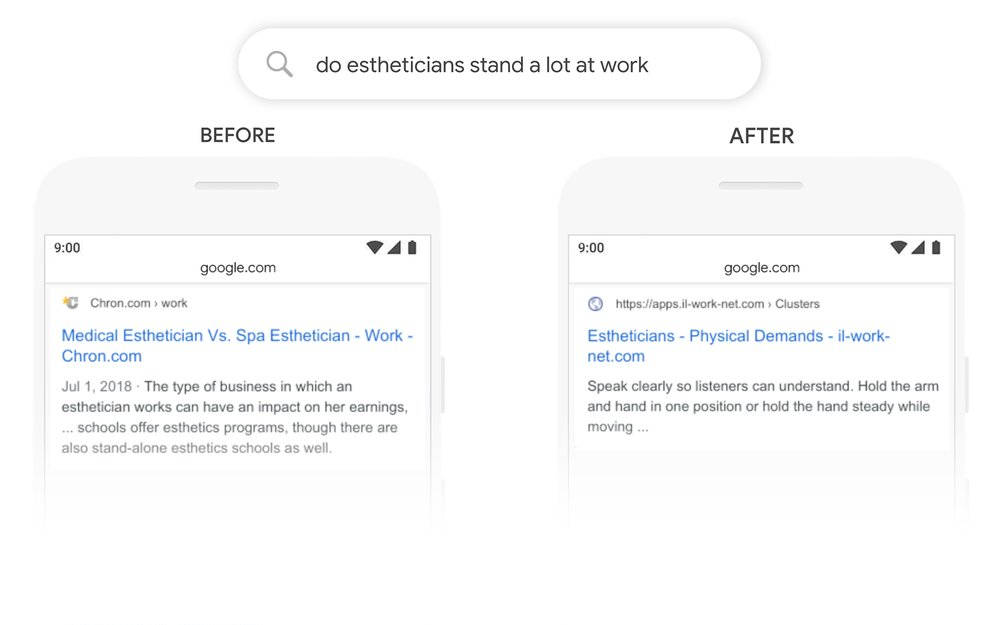
“Una estetista sta molto in piedi al lavoro” è una query di facile comprensione per un umano ma sorprendentemente complessa per una macchina. Innanzitutto una domanda senza il punto di domanda, una nuance difficile da capire da un sistema automatizzato, e in seconda battuta contenente una relazione piuttosto complessa e ambigua, soprattutto in lingua inglese, dove il sistema ha sostituito “stand a lot” con “stand alone” pensando ad un errore.
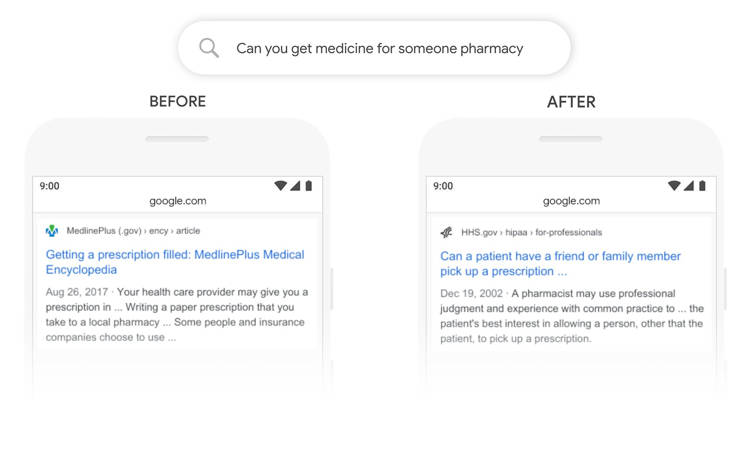
Questa query, letteralmente “Puoi prendere medicine per qualcuno farmacia” è un mix tra linguaggio naturale e una keyword secca (una sintassi alla quale Nayak ha dato un nome fantastico sul quale torno tra poco), con il termine “farmacia” aggiunto probabilmente quasi come un “refine” per dare contesto all’intera frase precedente, quasi un termine “aggiunto” mentre si formulava una query differente. Anche in questo caso la query è davvero complessa e ambigua, non immediatamente comprensibile neanche da un umano: eppure BERT riesce a comprendere tutto questo a tempo di query. Fantastico.
Mi ha fatto sorridere quando, nel comunicato di Google, si parli di “keywordese“, ovvero quello strano linguaggio coniato da chi, come me, cercava disperatamente di farsi capire da Altavista e soci parlando per keyword “canzone Vegeta Dragon Ball” poteva essere il mio (vano) tentativo di recuperare l’mp3 della canzone che accompagnava le apparizioni del mitico principe dei Sayan. Personalmente uso tutt’ora una sintassi simile. Ma se hai un sito che fa qualche migliaio di visite al giorno e ti metti a osservare le query in tempo reale da Google Analytics avrai molte sorprese, a volte anche molto buffe.
Mi capitò tanti anni fa di vedere una query che recitava, più o meno, “la dieta per dimagrire famosa a londra nel 1800“: era un riferimento ad una dieta accennata in una trasmissione televisiva del quale l’utente non ricordava il nome ma ricordava questo strano dettaglio. Un po’ come quando ci si chiede il “nome dell’attore biondo che faceva quello con la spade nel film che vidi mentre ero alle scuole superiori” si utilizzano riferimenti specifici solo a livello personale senza pensare che dall’altra parte forse non si possano intendere: questo rende Google impressionante quando riesce a dare la risposta corretta alla query. Detto questo l’ho già detto ma lo ripeto: il film “Her” penso possa essere uno scenario plausibile riguardo la nostra “relazione” con una entità digitale tra 10/15 anni, ovvero una vera e propria conversazione continua (per altro stanno lavorando proprio in questo senso su Android).
Tornando a quanto dichiarato, nella stessa intervista a Fortune Nayak ha ammesso, giustamente, che BERT, lavorando su circa il 10% delle query globali (dato che estrapolo io dalla dichiarazione che lavorerà “su un query su 10” in lingua inglese), e più precisamente tendenzialmente più vicine al linguaggio naturale (e quindi “lunghe” e “discorsive” come, ohibò, quelle vocali), peggiorerà alcune SERP: è normale e comprensibile che succeda perché, per quanto le menti che lavorano dentro Google siano tra le più brillanti del mondo, l’obiettivo di catalogare in modo automatico e rendere quindi disponibile in modo efficiente e puntuale a chiunque interroghi in modo imprevedibile la più grande banca dati del mondo rimane uno dei più ambiziosi nell’intera storia non solo della scienza ma della umanità intera. Non penso di allontanarmi troppo dalla verità dicendo che andare sulla luna probabilmente è stato “più semplice” (seppure qualcosa di più romantico ed eroico). Anche questo non ti ricorda qualcosa? Comunque sia, come riassume in poche parole sempre Nayak:
BERT non è la pallottola magica che risolverà tutti i problemi, c’è ancora molto lavoro da fare.
Nella pratica SEO di tutti i giorni l’impatto di BERT sarà lo stesso di quello che hanno avuto i precedenti update, almeno per me: la necessità di concentrarsi sempre di più nel comprendere cosa Google consideri rilevante e di qualità per un utente che digita una specifica SERP tramite lo studio della query stessa, allontanandosi dalle proprie arbitrarie idee. Come si è visto nei test Google inizia a capire le persone meglio di noi sotto tanti aspetti. Le studia in modo alieno, perché una A.I. non “pensa come noi ma più velocemente”, ma piuttosto computa in modo completamente diverso e ad una velocità mostruosamente superiore un problema, in questo caso la comprensione del linguaggio umano contenuto nelle query.
Non ci sono grandi rivoluzioni in vista nel mio metodo di lavoro. Per rimanere sorpresi da questo genere di sviluppi o ci si è chiusi a fare SEO senza guardarsi intorno per 3 anni o più semplicemente non si è seguita questa newsletter! BERT è una buona notizia secondo me.
P.S. se vuoi giocarci un po’ alcuni modelli pre-allenati di BERT sono disponibili e scaricabili liberamente in questa repository su GitHub.
P.P.S. come spiegato molto bene da questo articolo su Search Engine Land sarà difficile vedere grandi impatti relativi a BERT sui tool di terze parti: questo perché va a lavorare su query molto lunghe ed iper-specifiche che questi tool non hanno le risorse per studiare. Anche qui ci vedo un’opportunità per chi sviluppa software (nel caso questo facesse fare molti soldi a qualcuno vorrei almeno il diritto di acquistare azioni nel primo round, grazie!).
Gary Illyes parla di retroscena molto interessanti
Il buon Kevin Indig ha condiviso i suoi appunti riguardo un intervento di Gary Illyes il 10/14/2019 al Bay Area Search meetup di San Francisco, un evento organizzato da AJ Kohn (mamma mia quanto ci vorrei andare!). Ci sono un sacco di chicche da commentare e quindi tradurrò i passaggi più interessanti (approfondendoli quando mi sembrerà interessante farlo).
Robots.txt: Google ci vuole difendere da noi stessi
Domanda: Quanto spesso viene analizzato il robots.txt da Google? Potete mandare notifiche alle persone che fanno dei casini?
Risposta: Abbiamo dei sistemi che monitorano continuamente l’utilizzo del robots.txt che ricercano pattern nell’utilizzo (scorretto) del file robots.txt. Se ad esempio una grande azienda come Disney mettessere un robots.txt che blocca tutto avremmo un alert dal sistema.
(…)Abbiamo rimosso il noindexing dal robots.txt perché il 99% delle persone che lo utilizzava danneggiava i propri siti web.
Questa è una cosa che torna spesso nelle risposte: Google pare voglia “difenderci da noi stessi”. Se un’implementazione viene male interpretata (anche a causa del fatto che le dichiarazioni di Google hanno così poca credibilità dopo anni di mezze verità) si elimina il problema alla radice eliminando l’implementazione e quindi il possibile impatto negativo. Illyes ha dichiarato che toglierebbe il disavow per lo stesso motivo (e anche altro che ti lascio come sorpresa tra qualche riga).
Rel=nofollow: finalmente un motivo plausibile per i cambiamenti a questa implementazione
Domanda: I recenti cambiamenti al nofollow sono stati possibili grazie a qualche evoluzione a livello di sviluppo che vi ha dato un vantaggio particolare? Eravate più eccitati dall’impatto sui valori nel link graph o per la possibilità di utilizzare gli anchor text?
Risposta: Facciamo un passo indietro: che cosa abbiamo concretamente annunciato? Abbiamo semplicemente detto che da quel giorno saremmo stati in grado di utilizzare i link nofollow per il ranking e per il crawling dal primo marzo 2020. Se leggerai nuovamente l’annuncio vedrai che non abbiamo annunciato cambiamenti nel ranking: quello che abbiamo annunciato è che ora siamo in grado di utilizzare quei link.
Ho passato molto tempo in paesi non molto avanzati a livello SEO: sono luoghi nei quali molte persone mettono di default qualsiasi link in uscita in nofollow, cosa non ideale per un motore di ricerca che utilizza i link per fare il parsing del web. Metà della rete Internet è al di fuori degli Stati Uniti e dell’Europa e questo significa che non potevamo vedere metà del web.
Indig continua dicendo che Illyes ha detto, ad esempio, di aver tentato di convincere l’Indian Times di non utilizzare di default il nofollow. Questa del nofollow a prescindere è una pratica che purtroppo ho sentito citare anche in Italia. Le dichiarazioni riportate in seguito sono ancora molto interessanti.
Come utilizzeremo questo cambiamento del nofollow? Non lo so. Non c’è nessun cambiamento diretto al ranking previsto (…) Quello che succederà è che dal primo Marzo potremmo vedere cosa c’è dall’altra parte del link, ad esempio potremmo rilevare che c’è del malware. Una cosa molto utile.
Non dovete per forza aiutarci ad etichettare i dati usando il rel=sponsored, ma dovrete comunque usare il nofollow (quando è necessario N.D. Emanuele).
Sul fatto che Google onorasse sempre e comunque il nofollow come una direttiva sono state spese molte parole nella comunità SEO, e probabilmente non lo sapremo mai con certezza. Certamente però il discorso sull’implementazione sbagliata del nofollow, così come quella del robots.txt, da tutta un’altra prospettiva alla decisione di Google, almeno secondo me.
C’è anche un riferimento a quella che penso sia stata (ed è tutt’ora) una tattica molto utilizzata da Google: trattare con un mix di implementazioni e comunicazione qualcosa che è tecnologicamente fuori dalla loro portata. Nel caso del nofollow, non potendo arginare lo spam in modo adeguato, hanno fatto in modo che i webmaster, di fatto, glielo segnalassero loro stessi in modo indiretto, andando nel mentre (nell’arco di ben 14 anni, dal 2005 al 2019) ad affinare i sistemi che decidono autonomamente se un link sia “genuino” o meno. Questo vale anche, ad esempio, per il disavow: probabilmente quando Google sarà in grado di distinguere i link spazzatura che sono stati creati dal webmaster che li riceve da quelli che, a suo malgrado, sono stati puntati verso il suo sito toglierà la possibilità di utilizzare questo strumento. Capire questi meccanismi è molto importante per fare SEO, se non altro per dare il giusto peso alle cose quando si ragiona sul lungo periodo.
Ora voglio tradurre un passaggio che contiene quella che per me è una conferma importante.
Ranking: la SERP è una casa d’aste dove si compete per specifici posizionamenti
(queste dichiarazioni fanno seguito ad un lungo passaggio sui featured snippet che però era, secondo me, meno interessante N.D. Emanuele)… La SERP è una casa d’aste. Tutto ciò che vedi in SERP funziona facendo offerte per i singoli posizionamenti: chi “vince un’offerta” per una determinata posizione ottiene quel posto. Ma la prima posizione è generalmente “restricted” (che in questo contesto si può tradurre come “limitata” o “riservata” N.D.Emanuele).
(…) Quando i risultati compaiono e scompaiono costantemente, significa che la loro offerta è molto vicina a quella di qualcun altro e che i punteggi (che determinano il ranking N.D.Emanuele) sono davvero vicini l’uno all’altro. In questo caso, le piccole cose possono fare la differenza: ad esempio, se il tuo sito utilizza HTTPS e quello del concorrente non lo usa potrebbe divenire un vero e proprio vantaggio che può fartelo “battere” sulle SERP.
Non penso che questa sia una sorpresa per chi legge da un po’ questa newsletter. Sembro un disco rotto ma anche questa cosa la dico da anni: io credo che in SERP ci siano posizionamenti “dedicati” a siti con caratteristiche specifiche che vengono messi in competizione per quel singolo posizionamento. Ad esempio per “Prodotto X” potremmo trovare, semplificando moltissimo, una situazione come questa:
- In prima posizione un posizionamento dedicato al leader della nicchia del “Prodotto X” (ci torno);
- In seconda posizione un posizionamento dedicato al sito di un produttore diretto di “Prodotto X”;
- In terza posizione un posizionamento dedicato ad un ecommerce multimarca di “Prodotto X”;
- In quarta posizione un posizionamento dedicato ad un altro ecommerce multimarca di “Prodotto X”;
- In quinta posizione un posizionamento dedicato ad un articolo informativo da un blog generalista;
Quello che spesso non si considera è che se anche il sito “perdente” nella competizione per il quarto posto “perde” l’asta con uno scarto minimale questo non lo farà arrivare alla quinta posizione: questo perché quel posizionamento è riservato ad un’altra tipologia di sito. Il sito perdente andrà nel primo “slot” riservato a questo tipo di sito per questa query.
Sulla prima posizione c’è secondo me un discorso ulteriore da fare che ho ipotizzato ormai anni fa, trovando la mia teoria corroborata sia dalla pratica che, almeno secondo me (ma mi rendo conto che sia opinabile), dalle dichiarazioni di Googlers come questa di Gary Illyes: esistono siti di “prima fascia” che hanno comunque un “trattamento di favore” in quanto ritenuti talmente affidabili da avere degli “sconti” sulle analisi giornaliere e da potere essere leader di una specifica SERP. Penso che la prima posizione sia dedicata sempre a siti di questo genere, i quali posso al massimo alternarsi fra di loro e casomai possono venire “scalzati” da questo status di “prima fascia” solo in concomitanza di specifici update che fanno “un’asta” dedicata proprio all’assegnazione di tale “caratteristica”. Forse il mio è un bias cognitivo ma nelle affermazioni di Illyes, ripeto, trovo diverse conferme. Naturalmente mi interessano di più quelle pratiche, e ad oggi ho trovato più motivi per credere di aver azzeccato la mia ipotesi rispetto a quelli che mi fanno pensare di essere fuori strada.
Un altro aspetto interessante messo in luce da Gary Illyes è il peso che si deve dare a determinati aspetti in relazione allo stato dell’ottimizzazione SEO: piccoli dettagli quali l’HTTPS (che è stato definito tale da Illyes, e se non volete ascoltare me ascoltate lui) possono diventare determinanti al vertice, quando aspetti ben più importanti quali la rilevanza o la link popularity sono stati curati fino ad un livello ottimale e ci si trova ad una situazione di “parità” rispetto a questi aspetti importanti: è in queste situazioni che la cura dei singoli dettagli fa la differenza. A caldo mi vengono in mente:
- tecnologia: https, iper-ottimizzazione della velocità del sito (su questo ci torniamo nei prossimi mesi), affidabilità del server (a livello micro e non macro: se il server è spesso down si tratta di ottimizzazione “base” e non avanzata);
- implementazioni “avanzate” dell’accessibilità: lavorare sul contrasto del testo, lo studio della tipografia, la sostituzione di effetti javascript con HTML+CSS per le device che non utilizzano javascript stesso;
- iper-ottimizzazione della struttura a livello di pagina: tagliare le pubblicità che non funzionano sulle singole pagine, ottimizzare la navigazione secondaria sulle singole pagine, aggiornamento costante dei link in uscita, pulizia totale della struttura da redirezioni appunto in struttura;
E questi sono solo quelli che mi vengono in mente in pochi minuti. La chiave è avere l’esperienza e quindi le competenze per valutare correttamente lo stato delle cose, ed è il motivo per il quale nonostante abbia fatto un video di presentazione del canale YouTube con la maglietta delle Tartarughe Ninja io continui a lavorare con le aziende. Ma torniamo alle parole di Illyes.
Determinazione dell’intento di ricerca: Google è costantemente a caccia di “indizi” dagli utenti
Domanda: Come fa Google a determinare quali query devono essere rese local (in SERP)?
Risposta: Lascia che ti spieghi come funziona per gli “universal results”, ad esempio i map pack che provengono dall’archivio delle mappe (penso che intenda per rich snippet in SERP formati da feed da altri prodotti, ad esempio Google Maps, YouTube, Google News etc. etc. N.D.Emanuele). A quel livello la “causa” è l’attività di click sulle SERP. Metti che ad esempio qualcuno cerchi “Deadpool trailer” e, non essendo soddisfatto dei normali risultati di ricerca, clicchi sulla tab dei video. Per noi quello è un indizio. Quando questo si ripete migliaia di volte un “video pack” appare nella SERP (o la SERP si popola di soli video N.D.Emanuele).
La spiegazione è molto chiara ma ho un paio di “appunti” da fare:
- Ho osservato, in concomitanza con quelli che ormai chiamerei gli “pseudo-BERT” (ovvero i major core update degli ultimi anni) intere classi di query diventare local improvvisamente. Non sono convinto che questi dati siano sempre stati usati realtime, ma forse anche in questo caso si tratta di “accompagnare” un qualche sistema di machine learning in fase di apprendimento;
- Sul fatto che Google usasse i dati di utilizzo per implementare delle feature nelle SERP di specifiche query penso non ci fossero molti dubbi, quello che mi sorprende di queste dichiarazioni è che questa pare essere la prima causa che è venuta in mente a Illyes per questa casistica. Mi sorprende che non ci siano delle metriche “scientifiche” per pre-determinare l’apparizione di questi pack nelle query. Forse esistono dei pre-esperimenti, con SERP che implementano pack specifici che vengono quindi “scartati” osservando i dati di utilizzo;
Per altro questa cosa apre a diverse riflessioni sulla possibile manipolazione della natura di una SERP. Ti lascio correre con la fantasia perché mi vengono in mente solo cose che non vorrei fossero tentate/replicate. Continuiamo con una riflessione interessante sullo HREF-LANG.
HREF-LANG: ci abbiamo provato ma non siamo riusciti a semplificarlo
Domanda: Avete mai pensato di rimpiazzare la tag HREF-LANG?
Risposta: In realtà Gary (Illyes) e Cristoph (non mi è chiaro chi di preciso) hanno riscritto il parsing di HREF-LANG un paio di anni fa: sono stati per settimane in una stanza per cercare di semplificare la questione ma non ci sono riusciti. HREF-LANG è già la cosa più semplice da fare: indichi pagine “sorelle” da una pagina all’altra, è semplice e leggibile.
“Bill Hunt è uno dei maggiori esperti di HREF-LANG che io conosca. Gli ho detto “se hai un’idea migliore sono assolutamente disponibile ad ascoltarla” ma non siamo riusciti a trovare qualcosa di più semplice”
Internamente a Google questo causa dei problemi perché i cluster (immagino di relazioni N.D.Emanuele) utilizzano moltissimo spazio. Ad esempio Facebook utilizza Petabyte (migliaia di Terabyte N.D.Emanuele) per tutti i suoi siti nelle varie lingue.
Su questo non ho niente da aggiungere ma è interessante vedere come quelle che sembrano poche righe di codice, applicate alla scala sulla quale lavora Google, possano diventare un problema anche molto grande. Affascinante. Allaccia le cinture però che ora arriva un’altra affermazione che i meno attenti troveranno sorprendente.
E-A-T: sono solo delle linee guida. Quello che vogliamo fare è proteggere, letteralmente, le persone
Domanda: Parliamo di come si stabilisce il cosiddetto E-A-T (il concetto di “esperienza/autorevolezza/credibilità” espresso nelle guide per i quality rater N.D.Emanuele). I segnali dal testo possono impattarlo?
Risposta: Questo è uno di quegli argomenti sui quali non voglio sbilanciarmi troppo. Non mi pesa parlare degli snippet perché se anche voi sapete come funzionano non cambia praticamente nulla. Se però parliamo di YMYL (“your money your life”, ovvero i siti che trattano di argomenti ad alto impatto sulle vite degli utenti come la salute N.D.Emanuele) parlare troppo potrebbe danneggiare gli utenti (perché i SEO potrebbero approfittarsene N.D.Emanuele). Potrebbe essere pericoloso per le persone.
E-A-T è la versione molto semplificata di quello che i nostri algoritmi cercano di fare. Non sto parlando di un singolo algoritmo: ci sono probabilmente milioni di piccoli algoritmi che lavorano insieme all’unisono. Un algoritmo potrebbe supportare il pensiero della comunità scientifica (Gary dice espressamente di star citando le guidelines per i quality rater).
Ecco alcuni punti “spot” espressi da Illyes e citati da Indig:
- Le guideline per i rater riflettono quello che gli algoritmi stanno cercando di fare.
- Non esiste un punteggio E-A-T.
- Pensare che pulire il proprio profilo link posso risolvere la situazione dopo un core update è sciocco.
Illyes fa anche l’esempio di un amico che è stato impattato positivamente da un core update. Lo riporto anche se penso che farà arrabbiare alcuni miei specifici lettori… perdonatelo!
La mitica SEO senza link: Gary dice “si può fare, anzi, l’ho visto fare!”
Gary racconta la storia di un suo amico psicoterapeuta che dopo un core update ha osservato un enorme aumento di visitatori e chiamate dal sito. Diversi mesi dopo gli ha detto di essere sul punto di assumere più personale perché non era in grado di gestire il carico di richieste provenienti dalla Google Search. (Per ottenere questo risultato) Quello che ha fatto per 5 anni è stato semplicemente scrivere di ciò che sapeva: contenuti legati alla psicoterapia con link di approfondimento che verificavano la veridicità delle sue informazioni (immagino verso fonti “ufficiali”, per così dire, molto autorevoli come studi specifici N.D.Emanuele). Ha semplicemente creato contenuti, senza costruire un singolo link e senza usare dati strutturati. Ha iniziato ad utilizzare un template responsive solo dopo che Gary gli ha detto di farlo 7 volte. Non ha fatto “SEO estrema” e la sua attività è cresciuta fino a dare lavoro a 15 persone, delle quali 7 sono psicoterapeuti, lavorando solo sui contenuti.
Il caro vecchio Gary non ha mai avuto peli sulla lingua e, mentre ci descrive questo Eldorado SEO (e umano, oserei dire), forse (sicuramente) se ne frega di quanto farà incazzare le persone che lo ascoltano e lo leggono. Se devo dirla tutta il mio approccio alla SEO è molto simile a questo, perché la link building mi annoia terribilmente e la trovo un investimento meno sicuro che lavorare sulla propria piattaforma, a livello di contenuti, accessibilità umana e dei crawler, sulla User Experience, sulla User Interface e quant’altro. Inoltre, come spiegavo in un vecchio articolo che scrissi e che fece molto parlare anni fa intitolato (ora) “Il ruolo dei link e della link building, una volta per tutte” penso che Google aspiri ad escludere qualsiasi elemento manipolabile in modo “malevolo”, cioè al di fuori dal concetto di “miglioramento dell’esperienza utente”, dai suoi calcoli sulle SERP. Pensieri sparsi:
- Fare SEO in questo modo è “semplice”, nel senso che non richiede particolari ragionamenti? Probabilmente no. Questo perché richiede una conoscenza molto approfondita della propria utenza e uno studio costante del tempo dell’idea che ha Google stessa degli utenti che utilizzano le query alle quali possiamo dare risposta (e dobbiamo capire esattamente come fare);
- Fare SEO in questo modo è impossibile? No! Posso dirtelo perché io stesso lavoro in modo simile, per i motivi descritti sopra.
- La storia di Illyes è una favola che cerca di spostare l’attenzione dei SEO verso attività più “controllabili” da Google? Un poco si, ma di storie di successo simili a questa ne ho incontrate diverse in ormai 6 anni di consulenze SEO, persone che hanno saputo istintivamente produrre contenuti che hanno funzionato sul web e hanno, con un po’ di fortuna, evitato di commettere errori tecnici che precludessero la fruizione dei loro siti da utenti e crawler;
Forse per sedare l’ira dei presenti, in un atto di grande compassione qualcuno ha quindi fatto una domanda che molti vorrebbero fare a Gary Illyes.
Contenuti tosti con pochi link: the true story (?)
Domanda: Come si comporta Google quando deve posizionare un contenuto molto rilevante ma che ha un profilo link molto scarso?
Risposta: Il PageRank è solo uno di centinaia di segnali che utilizziamo per determinare il posizionamento delle pagine. Utilizziamo anche i link per altro ma non abbiamo strettamente bisogno dei link per posizionare le pagine.
Si tratta di qualcosa più difficile da osservare negli Stati Uniti ma c’è stata una persona che, presentando una conferenza in Norvegia, ha citato una sotto-pagina del sito di Porsche. Ha mostrato il posizionamento di questa pagina che aveva zero link, non ne riceveva neanche di interni dal sito che la ospitava. Era semplicemente inserita in una sitemap (XML probabilmente, come fa notare Indig N.D.Emanuele). Per le query che sono state mostrate la pagina del sito di Porsche era probabilmente la migliore scelta. Gary ha fatto notare che RankBrain potrebbe avere aiutato in questo caso.
“Specialmente in inglese e per altre lingue internet-mature (immagino che intenda lingue per le quali ci sia una comunità Internet “sviluppata” a livello tecnologico, e non parlo di hardware ma di implementazioni sul web), dove abbiamo una buona comprensione del web, non sempre ci servono i link (per determinare il posizionamento N.D.Emanuele).
Beh, queste sono considerazioni molto importanti che confermano quello che ho imparato tramite l’esperienza: per query iper-specifiche reali (non sto parlando dei nomi di fantasia dei mitici contest SEO di tanti anni fa), come possono essere query brand complesse (come ad esempio il nome di uno specifico prodotto di uno specifico brand), non c’è bisogno nemmeno di inserire le pagine ottimizzate in una vera e propria struttura: c’è bisogno solo di un’indicazione che dica al crawler dove queste pagine “risiedono”. Per questo spesso consiglio di creare domini-archivio per quei contenuti inutili rispetto alla semanticità della struttura principale ma che hanno una rilevanza storica e meritano di essere preservati: saranno reperibili su Google senza gravare sulla struttura del sito principale.
Passiamo ad alcune domande con risposte piuttosto secche.
Il valore dei link (short versione)
Domanda: I link nel footer valgono tanto quanto i link nel contenuto (principale)?
Risposta: No.
Nulla da dire.
Javascript: lo capiamo ma meglio non tirare la corda
Domanda: mettere un link in uno “span” invece che in un tag “a” è una buona idea o una cattiva idea?
Risposta: Non mi piace Javascript perché gli sviluppatori lo stanno utilizzando fin troppo: molte delle cose che vengono fatte potrebbero essere ottenute con HTML e CSS. Sarebbe quindi molto bello non avere tag span che diventano link dopo essere stati processati dal Javascript: a livello di indexing processare queste cose richiede molto tempo. Non mettete link negli span: usate le tag href e applicate loro lo stile che preferite. Il problema non è che Google non possa comprenderli: il problema è che a volte richiede molto tempo e richiede che venga fatto un rendering (specifico N.D.Emanuele). Tutto quello che richiede rendering richiede tempo.
Come dico sempre: “falla semplice“. Sento parlare spesso di soluzioni intricate per problemi semplici, magari per implementare un piccolo elemento grafico o un automatismo del quale si può fare a meno. Bisogna sempre fare un calcolo “costi/benefici” quando si parla di implementare Javascript, perché per quanto Google sia bravo a comprendere le pagine (GoogleBot utilizza da qualche mese l’ultima versione di Chromium, quella montata in Chrome per intenderci, e”vede” le stesse cose di un utente che utilizza l’ultima versione di Chrome) è sempre meglio rendergli le cose più semplici possibile. Parliamo ora della prossima domanda.
Cartelle differenti possono avere crawl rate differenti: perché?
Domanda: Parliamo di crawling. Tempo fa John Mueller pubblicò un link ad un documento che mostrava che Google assegna crawl rate differenti a differenti cartelle del sito. Come fa Google a determinare la crawl rate in queste situazioni?
Risposta: Fammi “rigirare” la domanda chiedendoti “Come struttureresti un sistema che fa questa cosa?”. Generalmente basta osservare i link: se ci si basa sul PageRank, ad esempio, e si fa la media di quello ricevuto dalla cartella si potrebbe già avere un’indicazione chiara su come comportarsi (AJ Kohn ha aggiunto che i link interni giocano un grosso ruolo sulla questione e Gary ha annuito).
Non impazzisco per come è stata riportata questa risposta, di fatto un poco vaga e, per mia esperienza, fuorviante. La vera questione è sempre quella della prominenza in struttura, a prescindere dal PageRank: se si propone una sezione del sito più spesso delle altre, ad esempio nella navigazione, è naturale che Google, pensando che noi la “proponiamo” nella pratica come più importante delle altre, possa pensare di controllare più spesso se i contenuti sono ok (ed avere meno remore nell’utilizzarli nelle SERP in quanto più affidabili). Dico “a prescindere dal PageRank” perché anche in siti che raccolgono molti pochi link, magari tutti in homepage, è possibile osservare il crawler soffermarsi su pagine e cartelle più prominenti in struttura.
Google inoltre sa benissimo quali sono le pagine di lista prodotto in un ecommerce e che queste sono molto importanti in un sito del genere. Ci sarebbe molto da dire in proposito (il crawling è una mia grande “passione” SEO) ma teniamo il discorso per un prossimo appuntamento sul blog ad esempio. Passiamo ad un’altra domanda sul tema.
Come nascondere qualcosa a Google (senza farsi “beccare”)
Domanda: Cosa bisogna fare se si hanno parti del sito che non vogliamo che Google veda? Pensiamo ad esempio alla ricerca a faccette (nella quale bisogna utilizzare dei filtri per navigare il sito in profondità N.D.Emanuele).
Risposta: Robots.txt rimane la via migliore per risolvere questo tipo di problemi. Si tratta di un sistema che ci si aspetta funzioni anche tra 25 anni, mentre sulle faccette non ne sarei così sicuro.
Bravo Gary, dillo a tutti i SEO del mondo, visto anche che Googlebot è sempre più curioso e irruento nel suo testare i siti nel web. Ultimamente ho avuto un cliente per il quale Googlebot, ignorando completamente il rel=canonical, ha iniziato ad applicare filtri a livello URL a pagine del sito che non avrebbero dovuto avere la versione con modificatore e creando un quantità mostruosa di pagine inutili e duplicate indicizzate (circa il 90% delle pagine indicizzate, nell’ordine delle migliaia). Gli unici due modi per essere sicuro che Google non veda un contenuto (o che se lo vede lo lascia stare e non torna a cercarlo) sono:
- robots.txt;
- nascondere il contenuto dietro un login con password;
Stop. Gli altri metodi, quali canonical, iframe, javascript e altre amenità hanno tutti delle “falle” e delle casistiche che li rendono inaffidabili. Spesso poi si tratta di implementazioni usate in modo scorretto dai webmaster, al di fuori del loro vero e proprio scopo. Un iframe non è fatto per nascondere una parte della pagina a Google, così come il rel=canonical non è uno strumento di strutturazione del crawling ma di gestione di vere e proprie pagine duplicate integralmente (e si sbaglia anche in questi casi!), non mi stancherò mai di dirlo. Bravo Gary. Passiamo ora all’ultima domanda.
Intento di ricerca: come fa Google a determinare il giusto mix su chiavi ambigue?
Domanda: Parliamo di intento di ricerca. Diciamo di avere un contenuto di ricerca con intento “fratturato”, ovvero che contiene sia risultati commerciali che informazionali. Come fa Google a determinare il giusto mix in questi casi?
Risposta: Una delle cose più importanti da considerare in questo caso è il posizionamento dei “token”: le persone dimenticano che abbiamo iniziato a usare le entità nella Search molto tempo fa. Osserviamo e valutiamo la nostra comprensione di un’entità in base a come la query è stata strutturata:
- Se ad esempio la query è “Gary the Snail” si otterrà un knowledge panel;
- Se la query è invece “Gary the Snail Amazon” sappiamo che l’intenzione è di navigare su quel sito;
Riflettiamo sul fatto che il knowledge panel sia utile o meno per la query: possiamo capirlo nel tempo in base a come gli utenti interagiscono con i risultati.
Quando gli utenti di Google raffinano le loro query (il classico “refine”) teniamo conto di questo fatto, soprattutto a livello di personalizzazione (Illyes fa notare che RankBrain gioca un suo ruolo, anche se non molto spesso, anche di queste situazioni). Se viene utilizzata una query ambigua si ottengono risultati ambigui che spingono l’utente a raffinare la ricerca.
La risposta è un po’ confusionaria, non so se a causa degli appunti del mitico Kevin Indig, che personalmente ringrazio per questo interessante scorcio nella mente di Illyes, o per la “cripticità” di Illyes stesso (che avendo visto live ho saggiato personalmente: è una persona molto particolare). Diciamo però che quanto viene detto può chiarire le idee a diverse persone su knowledge panel e sull’approccio di Google all’ambiguità, ovvero osservare cosa fanno le persone e prendere decisioni in base a quanto osservato. Niente di nuovo, almeno per questi lidi.
Se c’è una cosa che mi viene bene è vedere le cose prima degli altri: nel mio caso il problema è assecondarle tramite l’azione, ma questa è un’altra storia! Grazie Gary per le conferme e gli spunti di riflessione, e grazie ancora al mitico Kevin per aver condiviso i suoi appunti.
Altri articoli interessanti
Ecco una carrellata di articoli interessanti che non ho voluto/potuto approfondire e qualche curiosità che vorrei segnalarti:
- Google è in un momento “particolare” a livello aziendale: profitti in netto calo nel terzo quarto per il suo contenitore Alphabet (theinformation.com), una multa da 500 milioni di euro e quasi altrettanti di tasse arretrate in Francia (Reuters) e l’ennesima polemica con i suoi dipendenti che l’accusano, in questo caso, di spiarli monitorando eventuali riunioni interne tra i dipendenti stessi (Bloomberg) per evitare che si “organizzino” tra di loro. Non sono certamente un analista finanziario ma ho l’impressione che Google, come azienda, abbia perso la proverbiale “bussola” e che si stia perdendo tra le pressioni degli investitori, perché dopo la creazione di Alphabet non è stata più la stessa, e la pressione di una cultura sociale che non ha, per ora, saputo comprendere (o limitare: se ascolterai e leggerai alcuni dei documenti che sono stati fatti trapelare dai loro dipendenti capirai). Non dico che ci sia un fallimento in vista, assolutamente penso siamo molto lontani anche solo dal poterlo pensare, ma che si sia persa, aziendalmente, una certa brillantezza. Una situazione interessante da seguire;
- Segnalato da Riccardo Esposito, il CEO di Twitter ha dichiarato che la sua azienda non erogherà più advertising a tema politico. Traducendo uno dei tweet del thread “Le ads politiche su internet presentano sfide completamente nuova per la società quali l’ottimizzazione tramite machine learning dei messaggi e del micro-targeting, la proliferazione incontrastata di informazioni manipolatorie e i deep fake. Il tutto a velocità sempre maggiore, con sempre maggiore sofisticazione e scalando in modo travolgente“. Io ho due idee: che Twitter si sente in colpa per Trump e che la democrazia sta venendo distorta e messa in crisi dal web. Detto ciò questa è una notizia molto interessante. Forse, proprio perché non esistono tecnologie pronte per contrastare adeguatamente le fake news e che comunque di fatto si parla del tema molto delicato della censura in molti casi, questa è l’unica soluzione short-term efficace ed attuabile. Staremo a vedere;
- Come citato in una sezione precedente Google sta testando vere e proprie conversazioni continue tra utenti e assistenti vocali: sapete che divertimento quando le query saranno tutte, ma proprio tutte diverse? Gli sviluppatori di tool, così come chi si occupa di SEO, sono avvertiti. Personalmente ci vedo diverse opportunità, ne parleremo in seguito in altri lidi;
- Come segnalato da Merlinox aka Riccardo Mares è stata rilasciata la versione 12 di Screaming Frog. Tra le tante novità quella più gustosa, per quanto mi riguarda, è la gestione dei crawl via database: una figata pazzesca! Molto interessanti anche l’opzione per “spegnere” la ricerca di datapoint selettivamente su singoli crawl, come dice Riccardo qualcosa di molto utile su siti di grandi dimensioni (o se si vuole valutare solo uno specifico dato e si vuole risparmiare tempo, aggiungerei) e l’opzione per delimitare quali tipi di link il crawler debba seguire tra interni, esterni, canonical, paginazione rel=next/prev (è ancora vivo!), HREFLANG, AMP e meta-refresh. Come al solito non mi pento di aver rinnovato la costosa licenza e non mi meraviglio del fatto che non vengano offerti sconti: vale ogni centesimo (questo intervento NON è sponsorizzato!);
- In un articolo molto interessante apparso su cnn.com una hacker white-hat è riuscita, utilizzando informazioni personali reperibili dalle “normali” condivisioni sui social dell’intervistatore, a risalire al suo numero di telefono, al suo indirizzo di casa, a rubargli i punti fedeltà di un albergo e a cambiare la sua seduta in un volo già prenotato. Questo genere di hacking, chiamato social engineering, è stato svolto totalmente via telefono. Un articolo che apre a diverse riflessioni e che ti invito a leggere (o a guardare visto che c’è anche la versione video);
- Se non fosse chiaro, come dichiarato da John Mueller durante un hangout, avere del contenuto UGC (generato dagli utenti) di bassa qualità in grande quantità rende un sito di bassa qualità. La domanda era più specifica: gli errori di grammatica sono segnali di bassa qualità? Non se presi singolarmente, ovvero non se è l’unico “problema” della pagina, ma possono (logicamente oserei dire) un segnale di bassa qualità. Il sito va curato olisticamente in ogni sua parte se si vuole raggiungere lo spazio riservato all’eccellenza, e non solo in ambito search;
- Come annunciato sul blog per i webmaster di Google alla fine di quest’anno Googlebot inizierà a ignorare qualsiasi contenuto basato sulla tecnologia Flash e verranno indicizzate le risorse con estensione SWF, ovvero quella proprietaria proprio di Flash. Dopo averci regalato perle indimenticabili come “Badger Badger Badger” e “Salad Fingers” direi che questa tecnologia è entrata nella leggenda e, in barba a Google, non uscirà mai dai ricordi di noi pionieri del web. E anche dagli incubi dei SEO. Come si dice in romagna, “che flash!“. Si, l’ho detto. Perdonami;
- Come riportato da SEO Round Table secondo Google un link che viene da una pagina che riceve meno traffico rispetto ad un periodo precedente non diminuisce di valore. Martinez in un commento dice che Google non può misurare il traffico che va e viene da un sito web e quindi è logico pensarla così: è uno di quei rari casi dove non sono d’accordo con lui. Se anche si tratta di dati “incompleti” perché, fortunatamente, Google non ha il monopolio sui browser, i dati di utilizzo di Chrome sono troppo succulenti per essere ignorati secondo me. Un utente segnala che con un packet sniffer è possibile vedere che Chrome riporta solo i 404 ma io, nella mia ignoranza, rimango un poco scettico e mi aspetto che, tecnologicamente, Google sia capace di fare cose molto al di là della nostra immaginazione. Ma forse sono solo molto cinico (e ignorante);
- Attenti a nominare quella pillolina che ti fa vedere i puffi: come dichiarato candidamente da John Mueller il sistema che si occupa di controllare se il tuo sito è vittima di injection e quindi contiene spam di certi prodotti può vedere falsi positivi in siti legittimi. Quello che bisogna fare è controllare che non sia presente del cloaking, ovvero che venga mostrata una versione differente del sito al crawler e agli utenti. Una volta controllato che questo non sia il caso va semplicemente richiesta una revisione manuale. Niente di nuovo ma ogni tanto fa bene ricordarlo;
Il pensiero della settimana
Con quasi 7000 parole questa newsletter è forse la più lunga che io abbia mai scritto, e forse anche quella con i contenuti migliori! Detto questo purtroppo ottobre è stato un mese pesante a livello personale e ho dovuto rinunciare a partecipare a SMXL 2019, cosa della quale sono molto dispiaciuto. A quei pochi coraggiosi che si erano iscritti al mio speech sul crawling chiedo scusa, aggiungendo che in qualche modo quello speech lo farò, anche se probabilmente in una forma diversa dal discorso in aula. Spero anche di farmi perdonare con i prossimi contenuti che pubblicherò, tutti davvero interessanti, almeno secondo me!
Per concludere voglio ringraziarti per avermi dedicato il tuo tempo leggendo fino a qui! Se è la prima volta che leggi questa newsletter e non vuoi perderti la prossima, se vuoi leggere le precedenti o più semplicemente vuoi dire la tua su quanto è stato detto non devi fare altro che scrollare ancora un pochino:
Grazie nuovamente per aver letto fin qui e ti auguro un buon proseguimento!