- Google porta le favicon delle SERP mobile su desktop e, bersagliata da feedback e da teorie complottistiche (piuttosto verosimili) fa marcia indietro: parliamone;
- Onely.com ha pubblicato una interessante analisi su di un sito americano in ambito medical che ha perso tantissimo traffico a marzo 2019: riflettiamo sui perché, su cosa possiamo imparare noi in Italia e cosa significhi, a livello di business, trovarsi in una situazione del genere;
- Cos’è veramente il “potere” in un mercato?Google è un monopolio inattaccabile come lo erano Microsoft e IBM? Sapevi che Google vuole “superare” i cookies e lo user agent? Sai perché la Search Console ti ha tempestato di avvisi questa settimana? Sai davvero cos’è il Safe Search? Queste e tante altre novità selezionate da me per te!
Ciao e benvenuto alla edizione #46 della EV SEO newsletter, nella quale ho raccolto le novità e i contenuti SEO più interessanti che ho letto e selezionato per te nell’ultima settimana. C’è davvero tanto da leggere e quindi… buona lettura!
(PS: se sei iscritto alla lista email per favore apri la mail che ti è arrivata riguardo la newsletter, sennò i server mail pensano che mando spam!)

Le favicon in SERP, viste da diverse prospettive (e un colpo di scena)
É ufficialmente in rollout dale 13 gennaio la nuova versione delle SERP desktop presentata da Google su Twitter attraverso il suo account GoogleSearchLiaison, ovvero le SERP desktop con le favicon sopra al title, alla sinistra del domain name, sulla falsariga di quelle mobile.
O anzi… no. Con un colpo di scena (segnalato da Giorgio Tave su Facebook), dallo stesso account di Twitter del primo annuncio, il 24 gennaio Google ha dichiarato di voler ritornare, almeno parzialmente, sui suoi passi:
La settimana scorsa abbiamo aggiornato il look della ricerca su desktop in modo che riflettesse quello utilizzato su mobile da mesi: abbiamo quindi ascoltato i vostri feedback a riguardo. Vogliamo da sempre rendere la Search un’esperienza migliore e quindi faremo degli esperimenti con dei nuovi piazzamenti delle favicon, a partire da oggi. Nelle prossime settimane, mentre facciamo i nostri test, alcuni potrebbero non vedere le favicon mentre altri potrebbero vederle in posizioni differenti (…)
Segue quindi uno statement che di fatto ripete che, seppur l’assetto con le favicon ha avuto successo in ambito mobile e pur avendo rilevato dati positivi dai primi test su desktop Google vuole “incorporare il feedback” dei suoi utenti. Insomma questa volta il dissenso, almeno nella community dei webmaster e degli utenti sul web (almeno quelli “digitalmente consapevoli” come gli utenti di Reddit dei quali ti farò leggere una discussione), è stato troppo compatto e vocale per poter essere ignorato da Google, o forse semplicemente Google aveva fatto delle proiezioni che sono risultate sbagliate (riguardo l’impatto nel loro business di questo tipo di SERP) e sta prendendo l’occasione al volo per fare “l’azienda che ascolta“. Amin El Fadil si chiede anche su Fatti di SEO se la causa di questo “passo indietro”sia “Il dissenso o i tanti abusi nell’uso delle favicon?“. Lascio a te deciderlo.
Detto ciò sto scrivendo queste righe dopo aver “chiuso” la newsletter, che in teoria doveva essere inviata ieri (24 gennaio 2020), ma che era stata scritta prima di queste dichiarazioni. Mi sono chiesto “che faccio con il lungo articolo sulle favicon?“. Beh, oltre al fatto che Google non ha dichiarato di voler abbandonare il progetto, penso ci siano alcune riflessioni importanti, le quali rimarranno valide e soprattutto possono far capire come un pugno di pixel, o anzi (tendenzialmente) 10 pugnetti di 16 per 16 pixel possano potenzialmente cambiare le cose in modo molto marcato per noi operatori. E poi mi fa piacere documentare, per il futuro, il perché di certe decisioni ed aiutare a tenere alta l’attenzione su alcuni aspetti fondamentali del nostro rapporto con questa azienda che sembra aver perso la bussola.
NOTA: per chiarire ulteriormente, le prossime righe di questo articolo sulle favicon sono state scritte prima dell’annuncio di Google di un parziale passo indietro.
Partiamo dal mockup della SERP fornito da Google stessa:
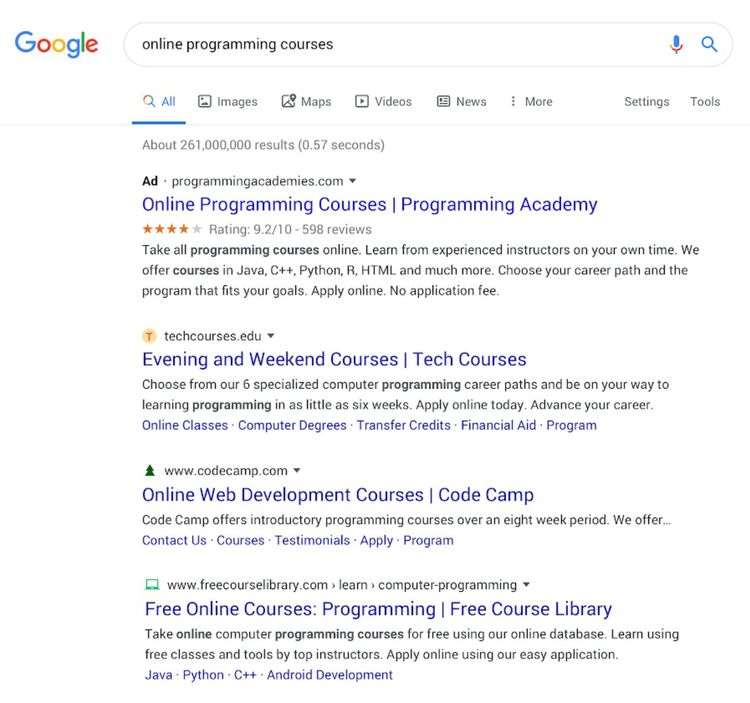
Ed ecco uno screenshot preso oggi, 22/01/2020, da me:
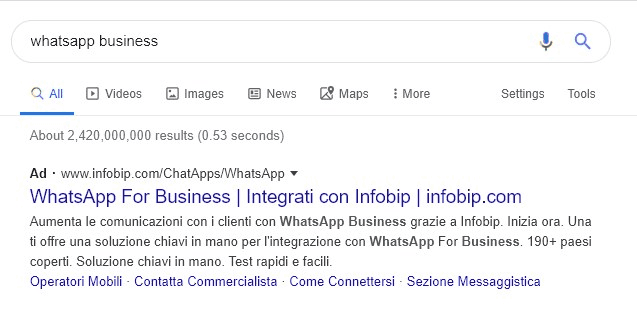
Occasionalmente, per onore di cronaca, appaiono anche ads come questa (probabilmente prese da shard di Google dove il rollout non è stato completato, se non sai cos’è una shard puoi leggerlo qui), con una label per gli annunci ben più visibile e distinguibile (anche se non come le vecchie label verdi):
A riguardo Google dichiara questo:
Questo formato mette il brand del sito al centro del palco, aiutando chi effettua le ricerche a capire meglio da dove vengono le informazioni, scansionare più facilmente i risultati e decidere cosa esplorare.
Mi permetto di dissentire: penso che purtroppo il centro assoluto del palco lo abbiano gli investitori e non più gli utenti, generando “update“, perché penso che non ci siano grandi “passi avanti” come un aggiornamento dovrebbe di solito portare, come questi.
Io non dico che Google debba lavorare esclusivamente per i webmaster, questo è impossibile e “insalubre” per un’azienda(anche se il suo successo è dovuto in buona parte proprio a noi operatori del web), però deve assolutamente ritrovare l’equilibrio perso tra servizio e profitto.
Circolano molte teorie “alternative”, rispetto alla versione ufficiale di Google, riguardo il perché le SERP siano state rese in questo modo e io vorrei citare una di quelle più interessanti: le favicon servono per causare la cosiddetta “ad blindness” verso le favicon stesse rendendo le unità pubblicitarie indistinguibili dai risultati organici. Questa interessante riflessione l’ho letta in un tweet di Rishi Lakhani, riportato in questo articolo di seobook.com.
Per intenderci “ad blindness” o “banner blindness” è quel fenomeno per il quale gli utenti di Internet, abituati alle forme delle unità pubblicitarie e ai conseguenti contenuti inseriti in esse (tendenzialmente fuori tema o comunque relativamente distanti dal motivo per il quale si sta visitando una specifica pagina), tendono a ignorarle in modo praticamente istintuale perché il loro cervello le reputa di scarso interesse. Si tratta di un fenomeno reale che è stato studiato e misurato in ambito degli studi sulla user experience delle pagine web.
Perché è verosimile? Perché se il nostro cervello, infastidito dalla “rumorosità” e dal basso grado di significato delle favicon rispetto alla nostra attività, scegliesse di ignorare questi nuovi elementi grafici una SERP come quella del mockup di Google verrebbe percepita così:
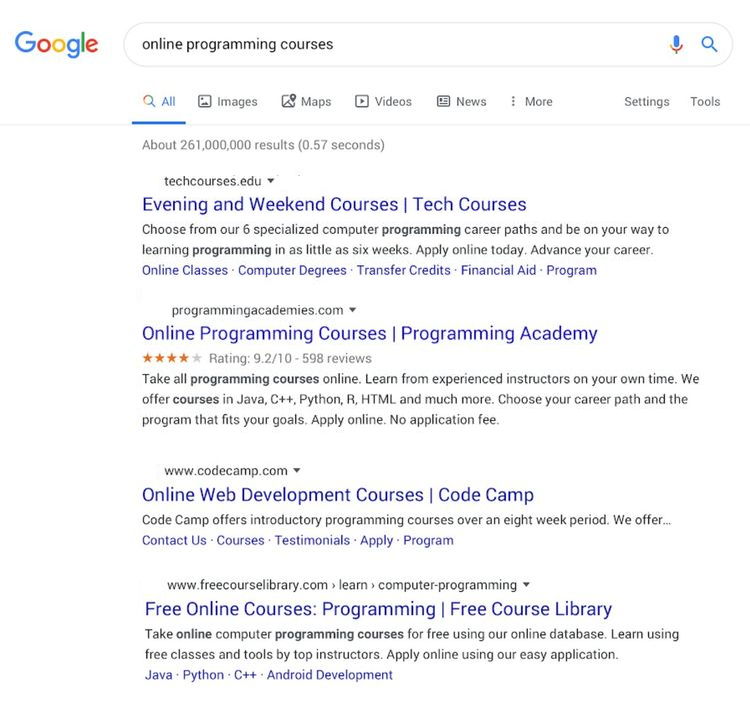
Per altro mi sono preso la briga di invertire il primo risultato del mockup, l’unità pubblicitaria, con il primo risultato organico, te n’eri accorto? Ecco, appunto.
Ora unisci questa cosa con il fatto che il CTR si distribuisce in SERP tra i risultati organici (o presunti tali) in modo non lineare, con la maggior parte dei recenti studi effettuati in materia che attesta il CTR del primo risultato sopra il 30% e un calo verticale da li in poi, passando per il 15% del secondo risultato e la singola cifra, il 9%, del terzo. E ancora non abbiamo preso in considerazione i rich result.
Una strategia deliberata da parte di Google che, a scapito di utenti e webmaster, si ponga come obiettivo quello di aumentare il CTR sulle pubblicità e quindi il fatturato dell’azienda non mi pare per nulla inverosimile purtroppo.
Qualunque sia la verità beh, la gran parte delle opinioni che ho letto in giro (naturalmente si parla di persone ” digitalmente consapevoli” e non dell’utente “medio”) non è propriamente positiva (presa da un thread su Reddit citato nell’articolo di seobook.com):
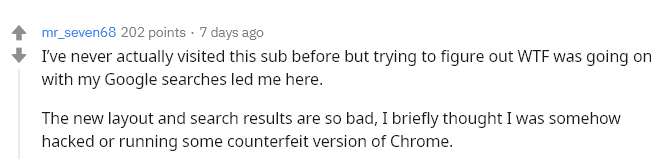
Certamente non sono le prime lamentele, e neanche le ultime. In un articolo su weareyard.com, citato sempre dall’articolo di seobook.com, appare questa immagine che parla da sola:
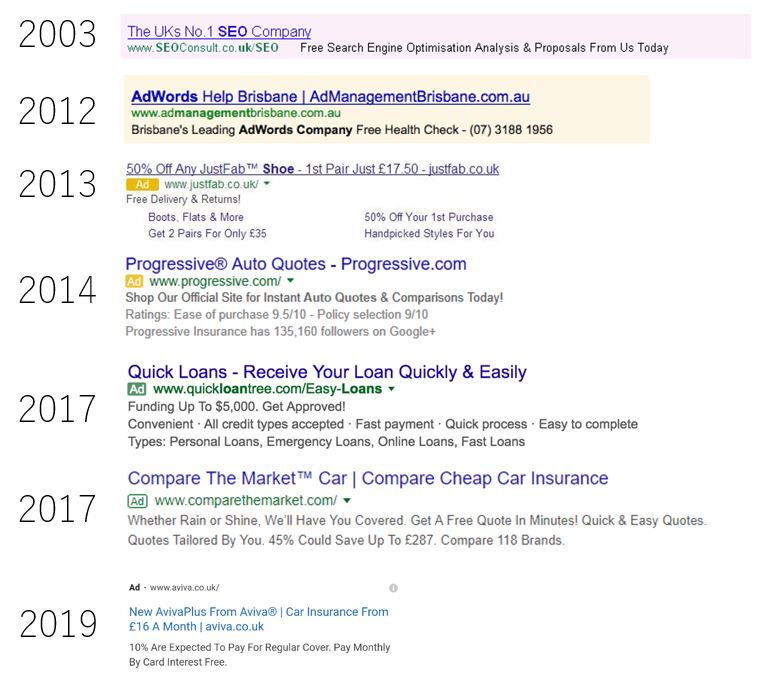
L’articolo contiene molte statistiche interessanti (anche se basate su di una piccolissima pool di 428 persone residenti nel regno unito, tra i 18 e i 60 anni d’età, 250 donne e 178 uomini), per altro relative al periodo della label verde per le ads:
- il 41% degli intervistati non hanno riconosciuto le ads in una SERP desktop, con o senza il knowledge panel;
- il 39% degli intervistati pensano erroneamente che ci siano in una SERP semplicemente popolata da molti rich results (query “banana”);
- da mobile gli utenti sembrano maggiormente capaci di distinguere le ads:
- il 62% è stato in grado di distinguerle nelle SERP con la label verde;
- il 73% è stato in grado di distinguerle nelle SERP con le favicon;
- il problema è che nelle SERP con le favicon senza le ads il 55% degli intervistati pensava che ci fossero comunque delle unità pubblicitarie: gli utenti sembrano essere meno capaci di distinguere i risultati organici;
Non male. Richard Falconer, presentando lo studio anche su Search Engine Land (Segnalato su Fatti di SEO da Giampietro Pregnolato), aggiunge una conclusione (che ho parafrasato per renderla più chiara) che fa riflettere:
La logica conclusione di questo approccio è che l’idea che i risultati nei motori di ricerca siano pagati venga “normalizzata” tra il pubblico (NOTA: abituandolo all’idea), rendendo possibile il fatto di poter gradualmente aumentare la quantità di “accettabile” di spazio per le ads nella percezione degli utenti del motore di ricerca.
Queste considerazioni, per quanto possano sembrare “teoriche” sono molto pratiche se riferite a qualcosa che probabilmente ti sta a cuore se stai leggendo queste righe: il mestiere o comunque l’attività del SEO, soprattutto nella sua accezione “meccanica” di “semplice artigiano” del link, del testo o del codice. Sono mestieri con le ore contate, minacciate dalle AI e dalle invettive di Google tanto quanto i tassisti da Uber. Bisogna sempre tenere alta l’attenzione rispetto alla realtà nella quale ci si muove per potersi prontamente adattare (o, se si è dotati di grandi capacità, adattarla come fanno quelli di Google). Secondo me è l’unico sensato di affrontare un mondo così dinamico, non solo in chiave web.
Vorrei citare anche una opinione “pro favicon“ sulla quale ragionare: diversi operatori (tra i quali Fabrizio Giancaterini con il quale ho avuto un breve confronto sul tema) sostengono che queste favicon siano (o per meglio dire fossero, sto scrivendo questo passaggio dopo il “colpo di scena”)un modo per Google di lavorare sui brand in SERP, dandogli più visibilità e quindi più peso nell’esperienza degli utenti. Una riflessione che ci sta tutta, per altro sarebbe un fattore che darebbe ancora più peso al “tiering” che teorizzo da tanto e del quale parlo spesso perché Google si renderebbe conto molto velocemente quando un brand viene considerato autorevole dal CTR anomalo delle posizioni “più basse” delle SERP. Mi piacerebbe pensare che Google fosse mossa, a questo punto della sua storia e visto quanto ha “fatto vedere” negli ultimi tempi, si muovesse mossa da intenzioni così “nobili”.
Detto questo noi webmaster, nella pratica, che ci facciamo con queste SERP con le favicon? Innanzitutto vorrei riportare un esempio proveniente da un Tweet ritwittato da Walid Gabteni, riportante un simpatico caso di “favicon spam“:
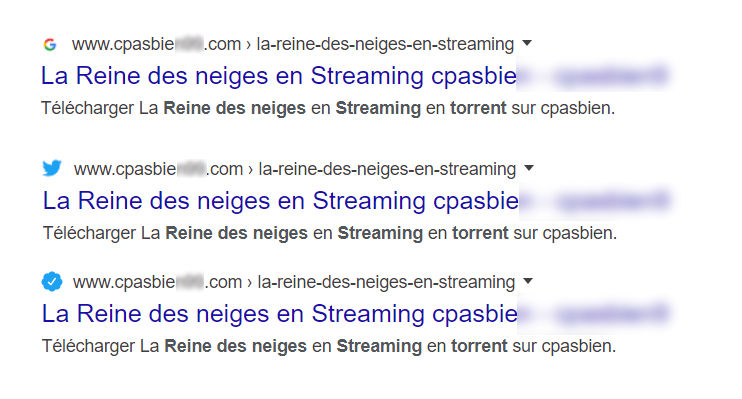
Certamente non hanno perso tempo… e non è neanche una cattiva idea (non lo fare, per carità!).
Scherzi a parte, riflettendo su attività meno borderline, la prima cosa che è venuta in mente a molti è che attraverso la favicon si può fare CRO (conversion rate optimization) con le varie manine che puntano, frecce, colori etc. etc.
Si può certamente anche fare brand awareness e brand differentiation perché, di fatto, si può utilizzare un elemento grafico in uno spazio comune e si può fare strategia a riguardo.
Un’altra cosa che mi è venuta in mente è che Google parla di “definire la favicon nella homepage” nella sua documentazione: e se per le landing page di query molto specifiche (nelle quali ci si può posizionare “facilmente”) utilizzassi le homepage di domini di terzo livello definendo quindi favicon specifiche per ogni landing? Può suonare complicato ma non lo è, e si potrebbe fare CRO a livello di pagina nelle SERP.
Queste naturalmente sono solo idee e immagino che vedremo un sacco di cose interessanti nelle prossime settimane, ti terrò aggiornato!
NOTA post annuncio del 24 gennaio: le ultime parole famose… Vedremo come si evolverà la faccenda.
E-A-T e il caso del crollo nelle SERP di everydayhealth.com
In questo articolo di Onely.com (sito che ho scoperto recentemente ma che vedrai, credo, spesso in questa newsletter) dopo una generica introduzione al concetto di E-A-T (expertise/authoritativeness/trustworthiness ovvero expertise/autorevolezza/attendibilità) vengono presentati dei semplici e chiari dati riguardo la caduta di everydayhealth.com, un sito a tema salute internazionale che dopo aver apparentemente scampato il primo giro di quello che da noi è stato chiamato “Medical Update” ha subito un crollo pazzesco a marzo 2019.
Cosa sia nella pratica successo è presto detto: il sito è stato soppiantato nelle SERP da siti con nomi più autorevoli, ad esempio di cliniche o pubblicazioni storiche, da editori storici, con autori più autorevoli. In questo caso parliamo di:
- mayoclinic.org, ovvero il sito di un’organizzazione non-profit dedicata all’erogazioni di servizi, educazione e ricerca in ambito medico con 4 campus dedicati sul suolo americano. Ha la sua pagina di Wikipedia;
- webmd.com, ovvero sito centrale di un network di divulgazione in ambito di medicina attivo dal 1996 (WebMD, nata come Healthscape) che riporta nel sito uno staff di 19 persone, delle quali 6 dottori, con una pagina dedicata ai premi vinti che viene paginata in 8 pagine, policy molto chiare e un modale che appare quando si clicca verso un link esterno e avverte l’utente che si sta uscendo dalla sua proprietà. La corporation omonima, quotata in borsa, ha la sua pagina di Wikipedia;
- medicalnewstoday.com, ovvero un sito e facente parte di un network di siti in ambito salute, Healthline Media, fondato nel 1999 e che riporta uno staff 22 persone, delle quali 8 sono medici e 8 sono manager con persone che hanno lavorato in posizioni sempre legate al management a Yahoo!, Disney, Microsoft e il New York Times. Ha la sua pagina di Wikipedia;
Negli about us dei siti nelle prime posizione trovate:
- Staff medico in chiaro con nomi, volti e biografie;
- Staff tecnico in chiaro con nomi, volti e biografie;
- Management con nomi, volti e biografie;
- Premi vinti;
Nei footer trovate:
- Policy chiare, diversificate e approfondite;
- Indicazioni chiare sulle possibili interazioni con la società che gestisce il sito (lavora con noi, contattaci, ricerca nella tua area etc. etc.);
- Certificazioni in ambito salute;
Capito la differenza? Per altro everydayhealth.com si è mossa in questo senso: guarda tu stesso com’era il sito a gennaio 2019 e confrontalo con la versione odierna.
Intendiamoci: questi sono aspetti importantissimi ma che non garantiscono il posizionamento in SERP delicate come quelle mediche: penso sia uno di quei casi dove la mia teoria del tiering, cioè della classificazione in “fasce” dei siti da parte di Google, venga applicata in modo più deciso. Credo esistano delle liste vere e proprie di siti che semplicemente hanno una corsia preferenziale grazie al fatto di essere autorevoli, attendibili e di affrontare le query con expertise. Non siti “raccomandati” ma siti che, non solo sul web, comunicano in modo molto chiaro chi sono, cosa fanno e perché lo fanno. Non è qualcosa di algoritmico, almeno a monte (e almeno secondo me, le mie sono tutte supposizioni che ad oggi hanno guidato le mie decisioni). Una volta “retrocessi” in questo senso ci vuole molto, molto tempo prima di poter tornare in vetta, anche perché ho sempre osservato movimenti del genere in concomitanza con i vari broad/major update i quali sono relativamente frequenti ma comunque distanziati di diversi mesi l’uno dall’altro.
Vorrei anche aggiungere che solitamente questo genere di considerazioni si affianca anche al fatto che i siti che superano un sito “caduto” per uno dei major update che hanno scosso il settore medico abbiano un setup tendenzialmente meno “losco”, che sa meno di “sito squalo” la cui unica “ragione di vita” è fare soldi. Il sito everydayhealth.com in questo senso non è il migliore degli esempi, perché navigandolo non da questa impressione e anzi ha molti elementi che fanno pensare il contrario dal mio punto di vista, ma prova a pensare ai movimenti in questo tipo di SERP che abbiamo visto in Italia. Non sto parlando di siti “brutti”, sto parlando di siti che sono chiaramente siti che, per quanto ben fatti, sono meramente delle content farm per veicolare traffico organico verso ads o affiliazioni. Questo genere di sito web non funzionerà ancora per molto, i tempi d’oro (in tutti i sensi!) penso siano finiti da un pezzo.
Intendiamoci numero 2: non c’è nulla di male a voler fare dei soldi con un sito web, per carità. Il problema è quando ogni azione viene guidata solo da questo obiettivo. Quando parlo del “perché lo fanno” parlo proprio di questo. La cultura aziendale di chi fa siti web non può essere solamente “soldi a tutti i costi“, è un modello che ha funzionato e forse, in certi casi, potrà ancora funzionare ma certamente non per sempre, perché non è questo il tipo di siti web che rendono le SERP un posto migliore per gli utenti, dove stanno meglio e dove quindi tornano, facendo si che Google fatturi miliardi di dollari con l’advertising. Si tratta di ragioni molto concrete, non di idealismi.
Tieni a mente che anche Google “ci fa una brutta figura” ad avere dei “partner” (perché di fatto i content provider, ovvero i publisher, lo sono) poco trasparenti e vuole delle entità che “gli facciano fare bella figura“ per i motivi che ho già citato.
So che quanto scritto farà agitare alcuni webmaster nostrani ma questo non è l’unico caso che ho potuto osservare di “ascesa nelle SERP” di siti fatti da entità “con le spalle larghe” al posto dei piccoli publisher. Prova a pensare ad un tuo amico meno “digitalmente preparato“:
- Darebbe più peso a quanto scritto da un copywriter non specializzato da 5/10/50 euro al pezzo o da un giornalista di un grande editore (NOTA: si lo so, spesso sono gli stessi ma cambia la percezione per i non-addetti ai lavori) oppure ad un medico con un volto e una storia (rintracciabile) alle spalle?
- Darebbe più peso ad un sito senza riferimenti e con uno staff nascosto o ad un sito che mostra nomi e volti o fa parte di un gruppo editoriale che pubblica anche in edicola o del quale si parla in televisione?
Che in fondo questo sia concretamente giusto o sbagliato, cioè che questi dettagli siano assolutamente e incontrovertibilmente sinonimo di qualità è naturalmente discutibile. Penso però sia più difficile discutere che, come giustamente individuato da Google, queste cose abbiano un peso nella scelta di riporre la propria fiducia, perché di questa risorsa molto preziosa si parla in questi casi, da parte delle persone “comuni”, che non hanno una preparazione e una consapevolezza come la tua sulle questioni digitali.
In Italia dobbiamo affrontare un altro problema che di fatto distorce la nostra percezione riguardo agli update: si parla di una scala molto minore, in termini di numero e preparazione dei player (Internet in Italia è un mercato meno maturo di quello americano). Nelle SERP mediche abbiamo visto affiorare siti che non paiono dissimili dai caduti perché, purtroppo per noi, la qualità media, a livello delle caratteristiche descritte sopra, è probabilmente minore.
Detto questo, se analizziamo siti quali:
- my-personaltrainer .it (che tutte le persone colpite dall’update reputano “discutibile” ma che si presenta molto, molto bene, rispetto alle riflessioni fatte in questa newsletter, perlomeno meglio del 98% dei siti colpiti, e dopo un tracollo è andato letteralmente in orbita secondo SemRush);
- fondazioneveronesi.it (cresciuto mostruosamente);
- ilfattoalimentare.it (“affermato” dall’update);
Questo per citare alcuni siti cresciuti o “confermati” con questi update le differenze, diciamo così, si notano.
Ti prego non mi portare come esempio la singola SERP con al primo posto il sito zeppo di ads e firmato da “redazione” perché questo non dimostra nulla: è naturale che ci siano eccezioni, errori nel sistema, test e altre anomalie che portino, magari anche per periodi lunghi mesi, a situazioni del genere. Ti invito però a pensare che questi fenomeni nel tempo si diraderanno, perché oltre a sviluppare la propria “visione” delle SERP Google spende milioni di dollari nello sviluppare processi e tecnologie capaci di rendere più rapido e, dal loro punto di vista, più efficace il sistema che filtra le SERP dalle “scorie digitali”, imponendo concretamente la sua visione in modo sempre più aggressivo ed efficiente. Sta a te decidere se e come fare business avendo come de facto partner Google: pensa soprattutto se per te sia sostenibile e conveniente assumere questo rischio. Cito il mio amico Benedetto Motisi:
Iniziereste un’impresa, un progetto, una qualsiasi idea in un ecosistema che cambia regole con la stessa frequenza con la quale il Cappellaio Matto urla “cambio di postoooo’ ogni 3×2?
Già. Le cose cambiano e solo chi si sa adattare potrà prosperare. Potrebbe anche essere giunto il momento di decidere che, se il progetto vuole andare avanti, la SEO non possa più essere la fonte principale di traffico. O magari che il progetto, nella sua prima incarnazione, ha finito il suo percorso SEO-centrico e deve reinventarsi completamente o, semplicemente, essere traghettato verso la sua fine. Un ambiente fluido come il web può cambiare molto velocemente e dobbiamo, ripeto, essere in grado di adattarci o, se siamo veramente molto bravi, a livello di Zuckerberg, Brin e Paige o Jack Dorsey, farlo adattare a noi.
Altri articoli e novità
Ecco una carrellata di articoli interessanti che vorrei segnalarti:
Sul monopolio di Google, Facebook e Amazon
Il signor Benedict Evans, oltre ad avere forse la mia newsletter preferita, ha scritto un articolo molto interessante che, personalmente, mi ha fatto riflettere e dato una nuova prospettiva sul futuro. L’articolo si apre con questa citazione:
Il potere non è rappresentato dalla ricchezza, dalla sofisticazione o dalla complessità. Il potere è la possibilità di far fare alle persone cose che non vorrebbero fare (cit. Roger Lovatt)
L’articolo parla di due aziende, IBM e Microsoft, le quali che si sono trovate in una posizione molto simile alle aziende tech attuali in odore di monopolio, ovvero Google, Facebook e Amazon. Senza stare a riportare tutta la storia, ecco l’estratto che mi ha colpito e fatto riflettere:
(…) Ciò mi riporta alla citazione che ho fatto all’inizio di questo post – cosa significa “potere”? Quando parliamo di “potere”, “predominanza” e forse di “monopolio” in ambito tech intendiamo due cose molto diverse che tendiamo a mischiare e confondere:
- Esiste l’idea (o il fatto) di avere il potere, il predominio o il monopolio intorno al tuo prodotto nel mercato di quel prodotto…;
- … ma questo non significa che tu stia controllando l’industria intera nella quale si muove questo prodotto;
Negli anni ’70 dominare il mercato dei mainframe (NOTA: come faceva IBM) significava dominare l’industria tech, mentre negli anni ’90 dominare i sistemi operativi PC (e i software per la produttività) significava dominare l’industria tech. Ora non più. IBM domina ancora il mercato dei mainframe e Microsoft domina ancora il mercato PC ma questi non sono gli aspetti dai quali può derivare il predominio sull’industria tech. Una volta IBM, e quindi Microsoft, avrebbero potuto far fare alle persone cose che non avrebbero voluto fare. Non oggi. Essere ricchi non significa essere potenti.
Secondo Evans queste aziende semplicemente non sono state capaci di trasferire il loro potere nei nuovi “cicli” delle loro industrie di appartenenza:
- IBM non ha saputo compiere il passaggio dall’era dei mainframe all’era PC mantenendo il suo predominio;
- Microsoft non ha saputo compiere il passaggio dall’era dei PC all’era del web e degli smartphone mantenendo il suo predominio;
Se negli anni ’70 le aziende si preoccupavano di cosa potesse fare la IBM e negli anni ’90 si preoccupavano di cosa potesse fare la Microsoft oggi, semplicemente, non lo fanno più.
Una nota interessante, che mi è parsa scritta appositamente per me, riguarda i dubbi sul fatto che aziende quali Microsoft abbiano perso il loro predominio per colpa dell’antitrust (e che possa capitare lo stesso a Google). In realtà la sentenza nel caso Microsoft contro Netscape e la “fatica” di dover gestire la situazione non hanno assolutamente inficiato gli sforzi sul mercato mobile dell’azienda, che anzi (e me lo ricordo pure io!) lavorò nell’ambito del mobile già da metà anni ’90 con Windows CE.
Quello che mise fine al predominio di Microsoft fu l’entrata distruttiva dell’Iphone di Apple nel mercato, il quale portò un paradigma completamente differente per queste device, “dal quale tutti dovettero ripartire“ per citare sempre Evans, che continua così:
Certamente, anche sono capire cosa fare in situazione come questa è molto difficile. Per quanto riguarda Microsoft, oggi sappiamo che la risposta giusta sarebbe stata quella di creare un sistema operativo completamente nuovo, senza la compatibilità diretta con le applicazioni Windows, e renderlo open source, distribuendolo gratuitamente. Immagina dire questa cosa a Bill Gates nel 2007 – ti avrebbe guardato come si guarda un folle.
Evans continua con una analogia molto significativa:
Si parla nell’industria tech di “fossati” (NOTA: intorno ai “castelli” rappresentati dalle aziende che hanno il predominio su di un mercato), meccaniche del mercato del prodotto che formano barriere strutturali per la competizione, per le quali non basta avere un prodotto migliore per entrare. Ci sono però molti modi nei quali un fossato può smettere di funzionare. A volte il Re chiede che vengano riempiti i fossati e buttate giù le mura del castello: è il deus ex machina dell’intervento statale attraverso le investigazioni dell’anti-trust e i processi.
A volte però semplicemente succede che il fiume cambia il suo corso, il fossato straripa, qualcuno apre un passaggio attraverso le montagne o semplicemente la via del commercio si sposta. Il castello rimane impenetrabile ma perde lentamente importanza.
(…)La competizione non è un’altra azienda di mineframe o un altro sistema operativo per PC: è qualcosa che risolve lo stesso bisogno dell’utente in modi molto differenti, o ne crea uno nuovo (NOTA: di bisogno) che ora conta di più. Il web non ha creato un ponte sul fossato della Microsoft: ha girato intorno al suo castello e l’ha reso irrilevante.
So di non avere fatto molto di più che tradurre e riassumere ma il concetto è molto interessante e mi pare un ottimo spunto di riflessione, e quindi ho pensato che comunque andasse bene così, non avendo nulla da aggiungere. L’articolo contiene altri ragionamenti forse altrettanto interessanti ma ho cercato di focalizzarmi su ciò che penso potesse interessarti. Fammi sapere cosa ne pensi.
Come scrivere un report SEO chiaro e veramente utile
Sono rimasto piacevolmente sorpreso da questa guida scritta da Cyrus Shepard su come creare dei report SEO veramente utili ed efficaci. Come ogni bravo americano lui parla di un “10X report”, io però che questa mania del “10X” la aborro ti posso dire che, semplicemente, descrive quello che deve essere un report SEO sensato, le quali caratteristiche sono:
- Attinente alla realtà: il report parla di metriche business possibilmente inserite in comparazioni sensate, ad esempio YoY (“year over year“, anno su anno);
- Concentrato sulla consapevolezza: il report parla delle metriche (ancora una volta) sensate, per esempio non parla di ranking ma parla di traffico organico su specifiche pagine, di ciò che finalmente (magari grazie a te!) funziona, di ciò che ancora non funziona, tutto questo riferendosi sempre ad elementi comprensibili per chi lo andrà a leggere;
- Promuove l’azione: il report può parlare di quello che si è fatto, si concentra sul presente ma riflette anche sul futuro con indicazioni pratiche e comprensibili a chi lo leggerà (anche se non sarà lui/lei a metterle in pratica deve poter capire) sui prossimi passi da fare;
Report come questi tolgono qualsiasi alibi, creano accountability e possono cambiare davvero le cose. Ottimo articolo!
Google SearchLiaison cerca di fare chiarezza sul rapporto tra SEO e Structured Data (per colpa della Search Console)
In un Twitter thread pubblicato il 16 marzo Danny Sullivan (o almeno credo!) ha voluto chiarire alcuni concetti fondamentali sulla Structured Data che purtroppo, anche dopo anni dall’apparizione dei primi rich results e infinite dichiarazioni di Mueller e soci in questo senso, non sembrano essere troppo chiari ai webmaster:
- L’inserimento di dati strutturati non ha un impatto diretto sul posizionamento nell’ambito dei classici blue links: Google non ritiene un sito più meritevole di posizionarsi perché implementa dei dati strutturati, al contrario ad esempio dell’implementazione di HTTPS che, secondo Google, è un fattore positivo per l’algoritmo (anche se non è chiaro ne in che misura lo sia ne per chi, feci un video qualche anno fa che andrebbe aggiornato ma che è tendenzialmente ancora valido nelle considerazioni);
- L’inserimento del dato strutturato, dando per scontato che venga utilizzato il giusto dizionario, che il dato sia formarlmente corretto e implementato in modo adeguato nel codice, è la condizione sine qua non per fare si che il sito appaia nell’ambito dei rich results in SERP. Influenza quindi il posizionamento in quegli specifici spazi nelle SERP, che è una cosa ben diversa!
- L’inserimento del dato strutturato può anche fare si che nel risultato organico appaiano elementi aggiuntivi come ad esempio lo star rating, il numero di calorie in una ricetta o la data di inizio e fine di un evento. Se vogliamo essere molto precisi tali elementi potrebbero portare benefici indiretti ad esempio influenzando il CTR (Click Through Rate) di tale risultato, arrivando quindi ad aiutarne il posizionamento. Si tratta però di qualcosa di indiretto e non qualcosa di computato direttamente dall’algoritmo di Google, il quale non collega l’implementazione dei dati strutturati con una maggiore possibilità del sito in questione di posizionarsi meglio in una specifica SERP;
L’ennesima ondata di dubbi è scaturita da uno dei terribilmente confusionari alert della Search Console (dei quali vorrei parlare in un contenuto dedicato in futuro) sulla mancanza del dato strutturato “nutrition.calories” nell’ambito delle ricette culinarie:
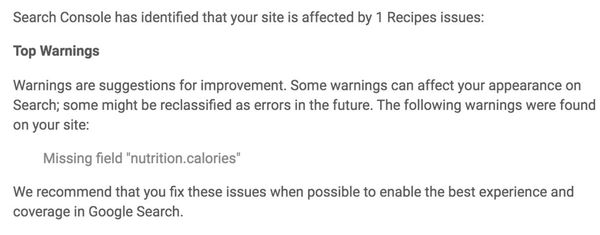
Come tante altre segnalazioni della Search Console, come dei 404 dopo che si sono cancellate volontariamente le pagine, la scelta delle parole “Top Warnings” in grassetto non è proprio azzeccatissima, si tratta di fatto di consigli “Ehi! Potresti inserire le calorie per rendere più completa la ricetta, ma va bene anche così!” oppure “Ehi! Ho visto tanti 404 nuovi, te li segnalo nel caso non fossero voluti. Se hai cancellato tu stesso le pagine consciamente puoi stare tranquillo!“. Temo che questo problema non vedrà molto presto una soluzione da parte di Google quindi non possiamo che, semplicemente, prenderne coscienza.
Google Assistant su Android e Chrome
Come riportato da 9to5google.com su XDA-Developers hanno trovato una notizia molto interessante inserita in due commit nelle repository di Chromium: ci sono piani concreti per sostituire la voice search dedicata su Android e Chrome con il Google Assistant, che verrà evocato ad ogni click o tocco sul bottone della voice search nella barra degli indirizzi di Chrome o in giro per il sistema operativo Android.
Nello specifico si parla di Chrome 85, versione che verrà rilasciata, secondo la schedule ufficiale, la settimana del 15 settembre 2020. Mi pare un ottimo modo per Google per dare ancora più lustro al suo assistente vocale “fisico”, inserendolo in modo ancora più preponderante nel suo “ecosistema” software, e soprattutto per poter raccogliere direttamente i dati dei propri utenti con un’unica fonte di dati, cosa che immagino sia molto comoda in termini di sviluppo, manutentibilità ed “economia computazionale”. Ne riparliamo a settembre.
Chrome vuole rendere i cookies più sicuri
Secondo questo post sul Google Webmaster Central Blog il giorno 8 febbraio 2020 verrà implementato in Chrome 80 il modello “secure-by-default” per il sistema dei cookies che verranno, di fatto, “riclassificati”. Riassumendo le parti salienti del comunicato:
- I cookies cross-site devono passare per una connessione HTTPS per mitigare il problema degli attacchi “man in the middle”, con un attaccante che si mette tra chi invia e riceve i cookies per leggerli e carpirne informazioni o per compiere azioni fingendosi il “proprietario” del cookie stesso (per maggiori informazioni Google segnala questa pagina);
- Per farlo gli sviluppatori devono utilizzare il nuovo attributo “SameSite=None” nell’utilizzo di cookies cross-site e devono nel contempo utilizzare l’attributo “Secure” per forzare l’utilizzo della connessione HTTPS (se ho ben capito! Non fidarti e controlla la documentazione!);
Di fatto queste implementazioni sono fatte per forzare gli sviluppatori a lavorare sulla sicurezza nello scambio di cookies: c’erano già attributi volti a queste funzioni ma erano poco implementati.
Secondo le dichiarazioni di Google questo sistema verrà implementato anche da Firefox e dai browser Microsoft “secondo la loro schedule“, diventando quindi lo standard;
Se sei uno sviluppatore e vuoi avere informazioni dettagliate sulla questione SameSite=None Google invita a visitare questa pagina su web.dev e a leggere la comunicazione di Google per una lista di “known complexities“.
Chrome vuole rendere deprecato lo User Agent
Segnalato in questo articolo di 9to5google.com, il piano di Chrome per arrivare a deprecare lo User Agent nel suo browser web è una novità piuttosto disruptive e interessante soprattutto per gli sviluppatori: se lavori con Internet da qualche anno sai benissimo quante tecnologie facciano leva proprio sullo User Agent ad esempio per servire un sito con un CSS differente o bloccare l’accesso a determinati browser (ricordo siti che ti bloccavano proprio se utilizzavi Internet Explorer!). La timeline prevista è la seguente:
- Da Chrome 81, il quale verrà rilasciato a marzo 2020, verrà deprecato il metodo “navigator.userAgent”: le applicazioni che lo utilizzano riceveranno dei warning dalla console di sviluppo di Chrome;
- Da Chrome 83, il quale verrà rilasciato a giugno 2020, Google smetterà di aggiornare lo User Agent e lo standardizzerà smettendo ad esempio di segnalare lo specifico update di Windows 10 utilizzato dalla device che monta il browser in esame;
- Da Chrome 85, il quale verrà rilasciato a settembre 2020, lo User Agent sarà unificato per ogni browser di ogni sistema operativo desktop. Lo stesso avverrà per le device mobile che però verranno classificate secondo la grandezza dello schermo;
Una volta arrivati a questo punto Google vorrebbe implementare una cosa che ha già proposto in bozza al W3C, ovvero lo User Agent Client Hints, UA-CH: di fatto si tratta delle stesse informazioni che verranno però “chieste esplicitamente al browser, il quale potrà rifiutare di fornirle“. Un grande divertimento per gli amici sviluppatori, sicuramente per i male-intenzionati ma anche per i bene-intenzionati temo.
L’autore dell’articolo giustamente parla delle implicazioni a livello di privacy, direi molto positive, nel caso lo User-Agent fosse dismesso. Correntemente, tra le informazioni che lo User Agent può rendere reperibili dai siti web e dalle web app troviamo:
- Tipo di browser;
- Versione del browser;
- Il sistema operativo sul quale gira;
- Il tipo di device utilizzata;
Queste, insieme ad altre informazioni sempre reperibili da siti web e web server quali il renderer per il WebGL potrebbero rendere il tuo computer, di fatto, identificabile. Se vuoi rimanere sorpreso, come lo sono stato io, ti consiglio di visitare questa pagina.
Lo ripeto: sarò cinico ma non penso che questa svolta pro-privacy di Google, che comprende la sua campagna anti-cookies e che sta ridefinendo praticamente ogni standard web a suo piacimento sfruttando il market-share di Chrome, sia dettata da una rinnovata voglia di fare gli interessi degli utenti di Internet: penso che voglia semplicemente togliere la possibilità alle altre aziende di reperire dati che può facilmente rilevare da altre fonti. Penso stia esagerando e che, come Microsoft vs Netscape, potremmo vederne delle belle…
Google ha deciso che data-vocabulary.org deve andare in pensione e non ha ancora imparato a comunicare in modo chiaro nella Search Console
Se hai un sito in WordPress e il 21 gennaio 2020 ti sei trovato diverse segnalazioni della Search Console riportanti l’avviso “data-vocabulary.org schema deprecated” puoi dare la colpa al solito Yoast: il plugin utilizza data-vocabulary.org per il dato strutturato delle breadcrumbs, un dizionario per i dati strutturati creato più di 10 anni fa e che di fatto è il predecessore di scherma.org.
Il problema concreto in questo caso è che, come annunciato nel Google Webmaster Central Blog (e come riportato da Search Engine Journal, dal quale ho reperito la notizia), Google ha deciso che dal 6 aprile 2020 data-vocabulary.org (un suo prodotto) non sarà più supportato a vantaggio di schema.org per quanto riguarda la generazione dei rich results nelle SERP, iniziando successivamente a bombardare (qualcuno ha ricevuto decine di email) le inbox dei webmaster di tutto il mondo con i suoi soliti avvisi poco chiari.
Per quel che riguarda Yoast immagino che il buon Joost e il suo team stiano già lavorando alla intuibile soluzione, ovvero quella di passare al codice tramite microdato, RDFa o JSON-LD (naturalmente questo vale per ogni implementazione di data-vocabulary.org, non solo le breadcrumbs di Yoast!). Personalmente consiglio di investire in questo ultimo formato, il JSON-LD, visto quanto è “spinto” da Google nella sua documentazione.
Se vuoi maggiori informazioni sulla storia di data-vocabulary.org e sull’impatto reale riguardo la necessità di aggiornare i siti indicizzati da Google ti rimando a questo post sul nuovo blog di Aaron Bradley.
Ora non ti rimane che spiegarlo ai clienti preoccupati dal solito criptico linguaggio della Search Console.
Il CEO di Pinterest parla del suo approccio proattivo alla qualità dei contenuti sulla piattaforma
Il CEO di Pinterest Ben Silbermann ha recentemente dichiarato in un podcast di Vox che:
La lezione che tutti hanno imparato negli ultimi anni è che se si vuole che vengano fuori cose positive dalla tecnologia Internet esse devono deliberatamente essere concepite in questo senso (…) se non ti assumi la responsabilità per quello che la gente vede sei, in un qualche modo, responsabile per ciò che ne consegue.
In virtù di questo suo pensiero la piattaformaha deciso di bloccare dall’agosto 2019 ogni contenuto generato dagli utenti riguardante i vaccini, sostituendoli con contenuti da fonti autorevoli quali il “National Institutes of Health and the Centers for Disease Control” americano, e facendo poi lo stesso con depressione e ansia.
Seppure, personalmente, sono sempre dubbioso nello sdoganare qualsiasi forma di “censura” mi rendo conto che questo sia un atto che denota una certa presa di coscienza e soprattutto una presa di responsabilità verso i propri utenti. Per questo, tanto di cappello. Inoltre sono sempre più convinto che Internet agisca ad una scala talmente alta in termini di volume che forse, e lo dico a malincuore, non potrà mai “funzionare”, a livello di “creazione di felicità e benessere per l’umanità intera e non solo per chi sa monetizzare“, senza che ci sia chi pone dei limiti. Si deve tenere presente però che purtroppo la stessa negatività, disinformazione e manipolazione che si vuole mitigare possono essere perpetrate da chi dovrebbe “dettare la via”. Il problema, in buona sostanza, rimane l’essere umano.
Le lenti che ti trasformano in Terminator
Forse il titolo è un pelo esagerato, nel senso che l’unica cosa che sembra presa da Terminator sono gli elementi digitali che fluttuano nel campo visivo, ma l’idea di avere delle lenti a contatto (graduate per altro!) collegate di fatto ad un computer per me è molto affascinante.
Presentate nelle sole funzionalità (non esiste ancora la lente vera e propria, hanno utilizzato un casco per la realtà virtuale) a Wired da Mojo Vision queste lenti vengono attivate guardando lateralmente e permettono, già in questa fase embrionale di R&D (dove le vere e proprie lenti ancora non esistono) di utilizzare app quali calendari, notifiche, teleprompter (il gobbo elettronico) e musica, tutto questo insieme a feature meno mondane quali la “night vision”. Fico!
Naturalmente siamo ancora molto lontani dal prodotto finito ma immagina queste lenti insieme ad un paio di cuffie wireless con una AI che fa da assistente vocale… il solito scenario che cito dal film “Her” praticamente. Detto ciò probabilmente queste lenti non le userò mai perché non riesco a indossare le lenti a contatto ma questa è un’altra (triste) storia.
Sulle “refinement bubbles”
Brodie Clark Consulting ha pubblicato questa semplice ma interessante analisi sulle “refinement bubbles”, ovvero i filtri “per tag” che possono venire stampati su diversi elementi della SERP, come ad esempio un carosello di prodotto o di immagini.
Si tratta di una feature molto interessante sia per gli utenti che per i SEO: permettono agli utenti di rifinire la propria ricerca, a Google di suggerire, prevedere e testare specifiche query ambigue e ai SEO/marketer di capire meglio come si dipanano le query ambigue e individuare classi di query per la propria nicchia (stringhe “radice” per le quali si possono effettuare permutazioni che creano insiemi di query). Si tratta di un argomento che mi piacerebbe molto esplorare e approfondire ma per ora mi limito a farti leggere questo bell’articolo.
Tu sai (davvero) cosa sia il SafeSearch?
Glenn Gabe ha fatto un post molto interessante su di un argomento molto poco discusso: il SafeSearch. Si tratta del sistema di filtraggio di Google che esclude dalle SERP delle persone che l’hanno attivato i contenuti ritenuti “adults only” in quanto riguardanti tematiche adulte quali violenza e pornografia. Gabe racconta di come rilevare eventuali problemi derivanti da questo filtro (problemi che alcuni suoi clienti hanno effettivamente avuto) o come prevenire, utilizzando la Google Vision API, eventuali problemi con i file immagine.
Interessante vedere come questa tipologia di problemi renda ancora più desiderabile la struttura URL per cartelle: pare che il SafeSearch tenda ad escludere intere cartelle del sito e Google stessa nella documentazione consiglia di mettere i contenuti adults only in un’unica cartella per poterla “censurare” segnalandola tramite dei meta-dati. Lettura che consiglio;
Matt mi manchi
Perché nessuno mi aveva avvertito della video-intervista al mitico Matt Cutts fatta da Barry Schwartz? Non ho ancora avuto modo di gustarmela ma pare si parli della vita del buon Matt, che è partito con la sua carriera di sviluppatore da una internship per lo NSA, la National Security Agency resa famosa anche in Italia dal caso Snowden, che ci ha raccontato come questi signori spiino praticamente tutto il mondo e ci (o almeno mi) ha fatto riflettere sulla quantità di microfoni e telecamere connesse che abbiamo nelle nostre abitazioni. Comunque sia, grande Matt, personalmente mi manchi;
Il pensiero della settimana
Devo dire che sono rimasto molto sorpreso dal passo indietro da parte di Google sulle favicon: evidentemente hanno pensato che il guadagno maggiore sulle ads sarebbe stato reso non profittevole dall’impatto sulla UX, ovvero che in buona sostanza non ne valeva la pena finanziariamente. Faccio fatica a credere che sia stato deciso per amore verso i propri utenti, lo dico con grande amarezza.
Detto questo noi due ci sentiamo nei prossimi giorni con un gradito (spero!) ritorno :).
Per concludere voglio ringraziarti per avermi dedicato il tuo tempo leggendo fino a qui! Se è la prima volta che leggi questa newsletter e non vuoi perderti la prossima, se vuoi leggere le precedenti o più semplicemente vuoi dire la tua su quanto è stato detto non devi fare altro che scrollare ancora un pochino:
Grazie nuovamente per aver letto fin qui, ti auguro un buon proseguimento!