Ciao! Buon anno e benvenuto alla edizione #45 della EV SEO newsletter, nella quale ho raccolto le novità e i contenuti SEO più interessanti (o almeno quelli che ho trovato tra i tanti che ho letto) delle ultime due settimane. Buona lettura!

(NOTA: se sei iscritto alla lista email ma hai trovato la newsletter da un posto diverso che dalla tua casella di posta ti chiedo per favore di trovarla e aprirla comunque da li: se non lo fai i server mail penseranno che non ti interessa e si arrabbieranno con me :)! Grazie per la comprensione!)
Analizziamo il Reddit Ask Me Anything di Bartosz Góralewicz
Il signor Bartosz Góralewicz è il CEO di Onely, un’agenzia di digital marketing specializzata in SEO tecnica, è nel board di DeepCrawl, è dentro al team di Ryte: insomma mica un babbaleo come me! Titoli e cariche a parte ricordo di aver letto alcuni suoi articoli in precedenza e “ci sa fare“: la cosa rende ancora più interessante la sessione di Q&A che si è tenuta su Reddit e alla quale ha risposto in modo interessante ad alcune domande che ti riporto/traduco/commento in seguito:
Domanda: in siti di medie dimensioni dove l’indicizzazione non è necessariamente un problema, quali dati bisognerebbe tenere sotto controllo riguardo l’attività di crawling da parte di Google?
Risposta: Se gestisci un sito web di medie dimensioni (definendo come medie un sito con più di 50mila pagine scansionabili), l’indicizzazione dei tuoi contenuti sarà una metrica che dovrai sempre tenere sotto controllo. Ci è capitato di osservare siti con solamente qualche centinaio di pagine con una percentuale significativa delle stesse non indicizzata. Dipendentemente dal tuo grado di preparazione tecnica partirei da:
- Google Search Console: il monitoraggio delle statistiche di crawling parte da qui. Non mi limiterei a “miodominio.com”: aggiungi tutti i sottodomini e tutte le risorse esterne che servono al rendering dei tuoi contenuti (Nota: immagino si riferisca a controlli “incrociati”). Assicurati di monitorare le performance del tuo server dal punto di vista della Google Search Console;
- Fai uno stress test: puoi ad esempio scansionare il tuo sito con un qualche centinaio di thread in contemporanea o comunque portare traffico/stress verso il tuo server. Controlla che questo non vada a inficiare il tuo Time To First Byte e controlla anche che tipo di performance verranno riportate sulla tua Google Search Console. Il comportamento del tuo server sotto stress è uno dei fattori chiave tra quelli considerati da Google per capire come e quando scansionare le tue pagine. Se Google “scopre” che con l’aumentare della scansione diminuiscono le performance rallenterà nel crawling, di molto;
- Architettura delle informazioni: assicurate che la struttura del tuo sito web sia semplice da seguire e comprendere sia per gli utenti che per i bot. Ci sono tantissime variabili in questo ambito e non posso approfondirle tutte, quello che però posso dire è che devi assicurarti di comprendere di volta in volta l’intento dei tuoi utenti (Nota: per una specifica query) offrendo una pagina che sia migliore di tutte le altre che concorrono per quella query (Nota: aggiungerei anche a livello di architettura bisogna considerare, per le singole query, l’esperienza che parte dalla pagina di atterraggio e si dipana all’interno o all’esterno del sito tramite i link che poni in ogni singola pagina, torneremo sicuramente sull’argomento, qui la risposta non era proprio “in focus“);
- Strategia di indicizzazione: ti sei chiesto cosa accadrà ai prodotti non più disponibili? Quali filtri dovranno essere indicizzabili? Il tuo sito potenzialmente genera “thin content”? Indicizza le ricerche interne? Quali sono le casistiche nelle quali possono venire generate delle pagine? Ti sei mai fatto queste domande? Sono SUPER importanti in qualsiasi sito che serve User Generate Content (Nota: e non solo! Sono problemi molto comuni su ecommerce, siti di news e altro, ne torneremo a parlare in altra sede). La strategia di indicizzazione è fondamentale per ogni sito di grandi/medie dimensioni;
- Log del server e monitoraggio degli errori: Dipendentemente da quanto tu sia tecnico potresti controllare i log del server ogni qualche mese (Nota: facciamo ogni qualche settimana…) e dopo ogni grande cambiamento nel tuo sito web, oppure potresti utilizzare il monitoraggio real-time dei log del server offerto da prodotti quali Ryte.com (Nota: vabbè, la marchetta ci stava dai);
Direi che sono tutti punti di grande buonsenso. Elementi quali la strategia di indicizzazione, che io di solito chiamo “policy di indicizzazione” per i clienti che stanno leggendo queste righe, è una delle prime cose che affronto in consulenza su grandi siti web perché, purtroppo, è una delle cose più trascurate e parte fondamentale di quella che per me è la componente numero uno della SEO ed è la mia specialità: la struttura delle informazioni! Aggiungerei che oltre a quello che viene indicizzato bisogna fare profonde riflessioni su tutto ciò che viene scansionato da Google: come non mi stancherò mai di dire uno dei capisaldi della mia SEO è che non bisogna far perdere tempo ne a Google ne ai propri utenti. Il problema è che per affrontare questo tipo di problemi bisogna utilizzare elementi potenzialmente distruttivi quali robots.txt: don’t try this at home (while not being supervised by a professional). Su questo argomento, come già detto, tornerò a parlare nel dettaglio nel futuro (prossimo?).
Ecco la seconda domanda riguardante un motivo di grandi discussioni nella community italiana: come si compete con i big del web sulle singole pagine?
Domanda: per molte delle mie keyword principali (Nota: sigh) su Google devo competere con le pagine interne di Pinterest, Etsy e Wikipedia: queste hanno un PageRank facile da raggiungere ma il problema è il loro domain rank (Nota: non esiste il domain rank. Il fatto è che questi siti raccolgono quantità astronomiche di segnali e sono siti di serie A+, cosa che porta grandi vantaggi sul posizionamento). La mia domanda è: possiamo davvero competere con queste pagine?
Risposta: se ci pensi non ti stai mettendo in competizione con l’intero dominio: sei in competizione con la pagina che risponde allo stesso user intent/query della tua. Il PageRank, per quello che ne capiamo noi SEO, non è importante quanto avere il migliore contenuto di tutti. Prova a dare un’occhiata alla query “JavaScript SEO”, siamo con ogni probabilità il sito più piccolo tra quelli che competono per questa query, ma:
- Pubblichiamo tantissimi articoli parlando di SEO e Javascript;
- Abbiamo pubblicato molte ricerche, esperimenti e articoli che hanno raccolto tantissimi link dalla community;
Pensaci: Pinterest o Etsy hanno un grandissimo punto debole, ovvero quello di non potersi specializzare e, francamente, di non avere a cuore le stesse query per le quali vorresti posizionarti (in quanto si posizionano per milioni di query).
Specializzati, conquista una piccola parte della tua nicchia e offri contenuti che siano 10 volte meglio che il secondo migliore che potresti trovare su Google.
Può suonare un po’ generalista e “fuffologica” ma la risposta che da è quella giusta: semplicemente non si compete tête-à-tête con Amazon, Wikipedia o Google, o almeno non lo si fa senza miliardi di dollari di budget, tanti anni a disposizione e la possibilità di fallire più volte. Quello che si fa è dare quello che loro non possono dare: la risposta più ovvia è la iper-specializzazione dei contenuti ma si può riflettere anche su tecnologia, multimedialità e modello di business. La vera arma in mano ai piccoli è l’elasticità, l’adattabilità e più in generale la libertà a livello di singola pagina contro la struttura tendenzialmente rigida dei big. Il problema è che questo spesso cozza con le premesse con le quali si fanno i siti web, soprattutto in campo affiliate, ovvero “low effort towards a passive income“, un risultato raggiungibile qualche anno fa dai pionieri ma molto difficile da conseguire nell’era dei “corsi per la libertà finanziaria tramite il web”. La realtà è ben diversa, come dice il mio amico Francesco Margherita in questo post dal messaggio molto diretto.
Dopo questa bella dose di dura realtà passiamo alla prossima domanda (composta da due domande):
Domanda: ho due domande:
- Quali sono gli aspetti tecnici che ritieni più importanti mentre analizzi un sito? In cosa cerchi delle “soluzioni veloci” per migliorarne le prestazioni SEO?
- Come analizzi siti multilingua internazionali essendo sicuro che quella indicizzata sia sempre la lingua giusta per la regione giusta?
Risposta:
1) Solitamente, quando cerco di analizzare i problemi SEO tecnici, parto con un crawl tramite Ryte/DeepCrawl (Nota: eh beh! Si può usare anche una soluzione desktop come Screaming Frog naturalmente). Le metriche più importanti per me sono:
- Quanti URL sono stati scansionati rispetto a quelli indicizzabili e unici;
- Robots.txt;
- Il “thin content“, i quasi-duplicati e tutti gli altri casini che possono sorgere in una struttura;
- Se c’è del “thin content” è possibile individuare dei pattern?
- Ci sono contenuti generati dagli utenti? Se la risposta è si, come sono gestiti?
- Controllo le dipendenze JavaScript con WWJD (What Would JavaScript Do (Nota: un loro tool gratuito). Quello che voglio sapere è innanzitutto se il contenuto è visibile con JavaScript disattivato, in seconda battuta se JavaScript modifica elementi chiave (contenuti, metadati quali i canonical, rel=noindex etc. etc.);
- Controllo il codice della pagina, sia il sorgente che il codice del render, per vedere se ci sono problemi tra quelli più comuni (Nota: immagino si riferisca a cose tipo metadati fuori posto, link malformati o script rotti e non a errori che “rompono” le pagine a livello di rendering grafico);
Dopo aver osservato la crawl data (o dopo averla osservata durante il crawl!) guardo se ci sono stati dei cambiamenti nella visibilità (Nota: credo intenda il posizionamento), cercando quali pagine sono state colpite e perché, ad esempio andando a controllare con la Wayback Machine se ci sono stati dei cambi di CMS o dei redesign. Controllo anche il “site:” del dominio perché è possibile trovarvi cose molto sorprendenti.
Questo è quello che mi viene in mente su due piedi ma molti dei problemi che troviamo li vediamo per la prima volta proprio durante questi controlli. Naturalmente i nostri SEO tecnici qui ad Onely (Nota: la sua azienda) hanno strategie/plugin/tool differenti con i quali compiono le analisi ma immagino che la maggior parte di noi controllerebbe prima le metriche che ho citato mentre analizza il sito di un nuovo cliente.
2) La tua è una buona domanda ma la mia risposta potrebbe deluderti: per quanto riguarda le strutture dei grandi siti internazionali solitamente controlliamo ogni mercato manualmente, controllando non solo che il markup sia corretto ma anche che in ogni paese si stia effettivamente posizionando il giusto contenuto (ti serviranno IP geolocalizzati per farlo)(Nota: penso intenda che per controllare se un sito serve la combinazione contenuto/lingua per un paese specifico serva un IP da quel paese, un risultato che si può ottenere con una semplice VPN).
Che dire, da sommelier del crawling e degli aspetti tecnici sono d’accordo con tutto quello che è stato detto in questa risposta. La domanda che raccoglie tutte le altre è “Sono sicuro che tutto il contenuto che si deve poter vedere possa essere visto da Google e gli utenti nel modo più semplice e intuitivo possibile e che quello che non si deve vedere da parte del crawler sia stato nascosto nel modo più deciso possibile?“. Gran parte dei problemi SEO, soprattutto quelli derivati dai major updates, viene proprio da qui, perché questi aspetti tecnici influiscono sul requisito fondamentale di un sito che si posiziona: la rilevanza alla query.
Mi spiace non aver partecipato a questo AmA, purtroppo (per fortuna) ero in uno dei miei rari periodi di “stacco” dal lavoro e pur avendolo visto (forse proprio stacco non era) mi sono forzato a non partecipare. Se gli argomenti interessano però posso lavorare su qualche contenuto ad-hoc, che ne dici?
Dalla “internet age” alla “AI age” secondo Robin Li, CEO di Baidu
Partiamo da qualcosa che ci riguarda potenzialmente da molto vicino: secondo il suo CEO e fondatore Robin Li il motore di ricerca cinese Baidu arriverà sui mercati internazionali “quando avremo trasformato la ricerca in un prodotto molto diverso” (sul significato di questa frase rifletteremo tra qualche riga). La notizia è che, in buona sostanza, a parte il fumoso quando, c’è un piano per “esportare” il software verso i nostri mercati dopo che l’azienda
Iniziamo col dire che viviamo in un mondo dove i media sono sempre più Cina-centrici, con le major quali la Disney che censurano prodotti occidentali (eccone un tristissimo esempio) per avere più appeal verso i quasi 1,5 miliardi di consumatori del mercato cinese, il quale è così appetibile principalmente per la pura scala: per intenderci la Cina è la seconda economia globale ed ha un’adozione mostruosa a livello di device mobile con 1,2 miliardi di contratti presso provider telefonici a Marzo 2019.
Proprio per questo lo speech di Robin Li inizia, prima di passare all’argomento AI e search, dagli smartphone. Parlando di 3 conseguenze del boom degli stessi sull’ecosistema internet in Cina:
- Le app sono diventate (e stanno diventando) “isole isolate“, ovvero ecosistemi dove vengono generati e consumati contenuti che sono poco accessibili ai motori di ricerca e più in generale a software di terze parti;
- I contenuti sono sempre più strettamente legati ai propri autori: se “nell’era dei PC” l’interazione avveniva tra un utente e un sito/pagina che avevi si un webmaster, ma del quale il 99% delle volte al visitatore non importava nulla. Nell’era dei social l’autore lega più strettamente, quando possibile, il contenuto alla sua persona, anche attraverso l’interazione con il fruitore del contenuto stesso;
- Video. Secondo Robin Li i video stanno diventando “la forma principale di contenuto” perché ad esempio lo speaker di un video è in grado di creare una connessione più profonda tra contenuto e fruitore del contenuto. Mi viene quasi da pensare che ora che i DeepFake sono facilmente generabili e accessibili…
Li ha fatto questo discorso per prepararci a quello che si apprestava a dichiarare, in modo molto candido, al pubblico in sala:
Nell’età delle AI la search si sta evolvendo a sua volta. Come sta venendo cambiata?
Vediamo diversi trend, il primo è che tipicamente il primo risultato è la risposta giusta (alla query). In questo momento il 60% delle query trovano risposta nel primo risultato.
Stiamo iniziando quindi a dare risposte dirette senza più servire un grande numero di link nei quali sono gli utenti a dover cercare la risposta giusta. Penso che questo scenario diverrà sempre più popolare o, per meglio dire, che una sempre maggiore quantità di query troverà risposta nel primo risultato attraverso un paragrafo di contenuto.
Oggi è il 60% ma arriverà al 70%, all’80% o anche il 90%. Le vostre query troveranno risposta direttamente invece di avere bisogno di consultare una lista di siti web o di link. Se ci pensate il “search problem” è, essenzialmente, un “AI problem“.
(…)La search è un “AI problem” perché di base voi, come esseri umani, esprimete i vostri bisogni e i vostri interessi sotto forma di query o di testo e a questo punto noi, utilizzando i computer per dedurre cosa state chiedendo, dobbiamo trovare una risposta rilevante. Se quindi pensate alle AI capirete che per definizione il loro compito è comprendere gli umani e servire gli umani.
In questo senso risolvere il “search problem” equivale a risolvere, in generale, lo “AI problem“. Si tratta di un problema complesso ma siamo sempre più vicini a risolverlo. (…) Visto che nella maggior parte dei casi il primo risultato è la risposta giusta (…) il resto dei link diventa ridondante.
In buona sostanza Robin Li prospetta un motore di ricerca che ci istruisce direttamente per ogni nostra domanda, bisogno o interesse. La risposta sarà forse “giusta“, ma per chi?
Danny Sullivan, in una intervista a CNBC pubblicata nel 2018, quindi non molto tempo fa, affermava questo:
(Noi di Google) Non siamo un “truth engine” (Nota: letteralmente “un motore di verità“). Una dei grandi problemi sui quali riflettiamo è come far capire al pubblico che il nostro ruolo è di fornire informazioni autorevoli e di qualità ma che quelle informazioni devono comunque venire processate in autonomia dalle persone. Possiamo darvi delle informazioni ma non possiamo dirvi “la verità” su di una specifica questione.
Un punto di vista piuttosto naïf. Se Sullivan parla sul serio, e non sta facendo semplicemente PR, Google non si sta rendendo conto fino in fondo dell’influenza che il loro software ha sulle persone e sulla società intera, il bias per il quale ciò che esce dal primo risultato di Google è, di fatto, corretto e “vero” per la maggior parte dei suoi utenti digitalmente meno consapevoli di noi operatori del web.
Temo proprio che la Cina ne sia ben più consapevole e, visto come si muove nella “sua” internet, tra censura e manipolazione, questa prospettiva non allieta i miei pensieri verso il futuro.
Il discorso continua con un altro punto piuttosto preoccupante: l’espansione dei propri interessi (secondo Baidu):
Non abbiamo bisogno di dare ai nostri utenti dei contenuti ridondanti. Una volta che abbiamo risposto alla query vorremmo darvi della conoscenza relativa al topic della query, ma non direttamente riguardo al topic della query. Per fare un esempio se tu cerchi “Van Gogh” e il primo risultato è una introduzione generale su Van Gogh, il secondo potrebbe essere una introduzione a Monet. Può anche non contenere la parola “Van Gogh”. Una volta data risposta alla vostra query possiamo espandere il contenuto secondo i vostri interessi (…). Nell’era mobile conosciamo molto di più sui nostri utenti rispetto all’era dei PC (Nota: confortante) e possiamo quindi esplorare gli interessi dei nostri utenti più in profondità. Possiamo dargli di più e fargli utilizzare più tempo. In Cina di media ogni utente passa 5 ore sulla sua devi mobile al giorno e questo dato continua a crescere. Le persone spendono sempre più tempo e, per quanto riguarda la search, possiamo rispondere alle query con un unico risultato, dando sempre più contenuti rilevanti ai nostri utenti.
Per quel che mi riguarda non sto leggendo previsioni o, per meglio dire, prospettive che mi rendono fiducioso verso il futuro. Queste persone di fatto decidono dove andrà Internet, come verranno cercate e chi e come risponderà alla ricerca di informazioni da parte di miliardi di persone. Non ho dubbi sul fatto che Baidu, come altre aziende cinesi, possa avere grande successo (misurato in adopters) anche in Europa e negli Stati Uniti. E questo mi fa paura.
Per altro la visione di questo signore non si ferma certo al suo prodotto:
Oggi (gli utenti cinesi) spendono 5 ore giocando o guardando brevi video utilizzando il proprio smartphone. Non guardano più la televisione. Internet ha cambiato radicalmente le modalità con le quali la gente fruisce l’intrattenimento. Penso però che stiamo per entrare in una nuova era, l’era delle AI. Le caratteristiche della nostra economia cambieranno: nel decennio a venire la definirei la “intelligent economy“.
Quello che intendo è che se internet ha cambiato il modo nel quale consumiamo e ci divertiamo, la intelligent economy cambierà il modo nel quale produciamo, migliorando significativamente la produttività per l’umanità.
Continuando a parlare di Internet:
Quando si ha uno “smart display” nella propria abitazione si inizierà ad utilizzare meno il proprio smartphone. Se si vuole sapere il meteo della giornata seguente basterà chiedere direttamente allo smart display. Con il telefono bisogna fare una lunga serie di azioni:
- Tirarlo fuori dalla tasca;
- Sbloccarlo;
- Trovare la giusta applicazione;
- Scrivere la propria destinazione;
Con le device “voice-first” l’esperienza è molto più diretta e comoda, la barriera di entrata è molto più bassa, non devi neanche essere alfabetizzato: devi solo chiedere con attraverso la tua voce e avrai la tua risposta.
(…) Nel prossimo decennio saremo sempre meno dipendenti dalle device mobili perché, dovunque andremo, saremo circondati da sensori legati a infrastrutture che potranno rispondere ai tuoi quesiti, che possono servirti. Non dovrai tirare fuori il tuo smartphone ogni volta: è il potere delle AI.
Il suo discorso continua descrivendo le AI applicate a vari aspetti della vita, mondana o meno. Merita un’ultima menzione questo passaggio:
Più avanti, basandosi su informazioni e contenuti digitali, i computer potranno imparare come pensi. In futuro non è difficile immaginare Tim Cook che, volendo valutare se la Apple debba o meno lavorare su di un progetto di veicoli a guida autonoma, chiede a Steve Jobs, la copia digitale di Steve Jobs, se questa sia una buona idea. Grazie al fatto che molte informazioni su Steve Jobs sono archiviate su Internet i computer potranno imparare come Steve Jobs pensava. Questo rende Jobs immortale. Ma non solo lui: le informazioni di qualunque persona possono essere archiviate, comprese e rese disponibili quando necessario. In questo senso le AI vi renderanno immortali.
Mi spiace, perché sicuramente qualcuno penserà che sono semplicemente retrogrado o tecnofobico, ma non credo che questa sia una buona prospettiva per il genere umano. Lasciando stare gli scenari a la Terminator penso che l’uomo semplicemente non sia biologicamente programmato per essere sereno in una società del genere, e che al massimo potremmo aspirare ad una piacevole anestetizzazione di noi stessi, cullati e nel contempo manipolati da chi continuerà a realizzare le proprie ambizioni.
A prescindere dall’etica un futuro del genere parla anche di un profondo cambio di paradigma riguardo il nostro lavoro: chi non saprà adeguarsi all’inevitabile (forse non nei termini di Li) invasione delle AI in ogni tecnologia, staccandosi dagli automatismi di mansioni di fatto meccaniche e automatizzabili come lo sono molte di quelle presenti nel nostro lavoro, avrà un brusco risveglio. Non c’è mai stato così bisogno di avvicinarsi alla propria sfera umana, l’unica parte di noi veramente inimitabile, come in questo periodo. Non solo per essere “realizzati” ma, temo, per sopravvivere. Intuito, sensibilità, personalità.
PS: ho scoperto di avere spesso detto un’inesattezza: non fu Google con il PageRank il primo a valutare utilizzando i link un corpus documenti per classificarli ma fu RankDex, una tecnologia sviluppata proprio da Li e citata proprio nel paper originale del PageRank. In buona sostanza ha lo zampino anche in Google.
PPS: è in corso un dibattito molto interessante su degli sviluppatori che hanno cercato di brevettare due invenzioni create da una AI e sono stati respinti dall’ufficio dei brevetti europeo. Sapevi che anche in campo artistico non si può applicare il copyright alle creazioni di una AI? Tutti quesiti molto interessanti sui quali iniziare a riflettere seriamente.
Altri articoli interessanti
Ecco una carrellata di articoli interessanti che non ho voluto/potuto approfondire e qualche curiosità che vorrei segnalarti:
John Mueller pwnz Reddit
Partiamo in bellezza con questa blastata livello Mentana di John Mueller su Reddit (segnalata da seoroundtable.com):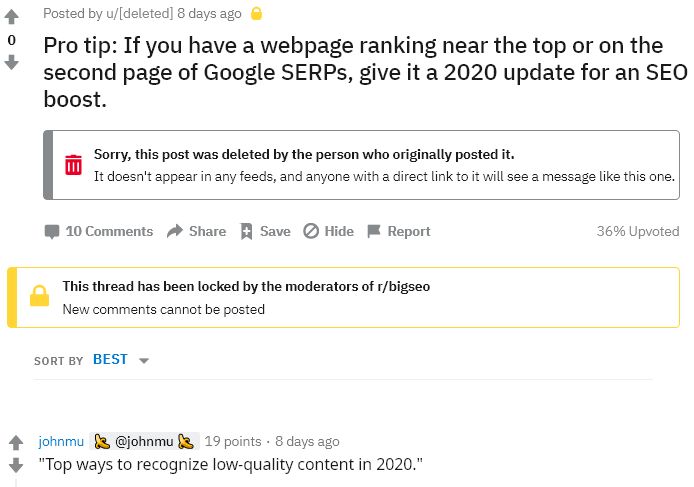
Chrome 80 implementa “quieter permission UI for notifications”
Stavolta devo dire che sono anche io colpevole di aver rotto le balle indiscriminatamente al prossimo e probabilmente finirò nella casistica della “quieter permission UI for notifications” che verrà rilasciata in Chrome 80. Traduco dal blog:
Per proteggere l’utilità del servizio di notifica per gli utenti Chrome 80 mostrerà, in specifiche condizioni, una interfaccia per i permessi di notifica che riduce il grado di interruzione dell’esperienza utente delle richieste di permesso per le notifiche (push).
Sono finiti i tempi della corsa al click sul no per le richieste di notifica? Only time will tell. Scherzi a parte se ben implementato mi pare un’ottimo passo avanti. Vi rimando al post sul blog di Chromium per i dettagli tecnici della cosa;
Amazon ha più di 200 milioni di Alexa installate
Siete indecisi sul fatto che gli assistenti vocali siano da considerare qualcosa di più di un gimmick (a Modena si direbbe “un zavaglio“)? Amazon ha dichiarato durante il CES (Consumer Electronics Show) 2020 di avere “centinaia di milioni di device (Alexa) installate“: l’autore dell’articolo ne desume che dai 100 milioni di device installate ad inizio 2019 siamo passati ad oltre 200 milioni.
Il dato incredibile non è tanto la nuda quantità quanto l’accelerazione nell’adoption di queste device (una frase un po’ da imbruttito ma ci stava dai) e dalla cifra spropositata, più di 100mila, di device smart compatibili. Nel mentre, come rivelato da un’inchiesta sempre lo scorso anno, il personale di Amazon ci ascolta. Questa newsletter sembra un po’ “complottista” ma sono dati fattuali ed è bene che tu lo sappia, semplicemente. Sallo! Pronto a fare la SEO del tostapane?
Chiude il mitico blog “SEO Skeptic”
Salutiamo il blog “SEO Skeptic” del mitico Aaron Bradley (il mio personale “guru” riguardo la structured data, penso avesse fondato lui il gruppo più fico di Google+ sull’argomento), chi fa SEO da relativamente qualche anno come me avrà sicuramente letto qualcosa di suo.Molto interessante scoprire che il buon Aaron da “SEO” diventerà lo Knowledge Graph Strategist di Electronic Arts, un’azienda gigantesca del gaming (che negli anni ha inglobato e ucciso tutte le mie software house preferite, ma questa è un’altra storia).
“The search engines’ pivot from the provision of linked document summaries to the provision of facts about things is certainly the most significant change that Google et al. have ever made to their approach to search, and it has enormous implications not only for search marketing, but for marketing in general – and, dare I say, for digital epistemology.“
Un grosso “in bocca al lupo” ad Aaron per la sua nuova (ed innovativa) avventura da seguire sul sito https://thegraphlounge.com/!
Facebook vs Shopify? Pare di no
Il CEO di Shopify Tobi Lutke risponde ad un tweet molto popolare di 2PM che, riportando una dichiarazione di Mark Zuckerberg nella quale dice che “Nel corso della prossima decade vogliamo creare degli strumenti per la vendita e il pagamento per le piccole aziende, in modo che queste abbiano accesso alla stessa tecnologia che fino a quel punto era accessibile solo alle aziende più strutturate“, asserisce che Facebook vuole competere direttamente con Shopify e le altre SaaS (software as service, di base le app in cloud) che si occupano di ecommerce.
La risposta? “Shopify ha collaborato con Facebook su ogni suo esperimento in ambito di commercio degli ultimi 10 anni“. Per lui più canali di commercio attivo esistono più un software multi-canale come Shopify prospererà.
Personalmente, come dice un commentatore, penso che siano mosse come questa che possono davvero portare al rischio di vero e proprio monopolio e quindi alla divisione forzata di Facebook o Google in più aziende. Probabilmente non accadrà mai (purtroppo) ma rimango molto dubbioso sul genere di impatto che questi colossi possono avere usando come leva i loro immensi bacini di utenza per invadere, velocemente e in modo distruttivo, altri mercati. Staremo a vedere.
Migrazione di un sito web? Meglio tutta in un colpo solo (parola di John Mueller)
Questa me l’avete sentita dire più volte: se fai una migrazione falla a livello massivo, tutta in un colpo solo per non confondere Google. L’ha confermato John Mueller durante un English Google Webmaster Central come riportato da SEOroundtable.com. Ora lo sai anche tu. Aggiungo che secondo me un certo numero di URL migrate fanno da “trigger” per il reset di alcune metriche che dovranno essere ricalcolate: meglio che questo avvenga in un’unica istanza, idealmente parlando;
Project Artemis
Come riportato da questo articolo del San Francisco Chronicle Microsoft ha iniziato, dal 10 gennaio, a dare il licenza l’utilizzo del suo tool anti-pedofilia “Project Artemis“, attualmente già utilizzato sul sistema di chat dell’ambiente Xbox (la console per gaming di Microsoft). Si tratta di una tecnologia d’analisi del testo che da un rating allo storico delle conversazioni in modo da poter allertare un revisore umano in caso vengano rilevati pattern compatibili con la predazione di minorenni via chat. Uno scopo nobile e una tecnologia molto interessante ma rimango sempre un po’ dubbioso sul fatto che ogni conversazione venga, di fatto monitorata nella sua interezza. In ogni romanzo distopico parte da queste cose comprensibilissime e assolutamente condivisibili (e divisive, immagino che qualcuno si incazzerà per quello che sto scrivendo) per poi arrivare al controllo totale delle conversazioni. Un discorso molto delicato. A prescindere da qualsiasi opinione secondo me è giusto che più gente possibile sia consapevole di questi sviluppi in termini di controllo e quindi voglio riportare la notizia;
Native advertising ai massimi livelli!
Voglio citare questo articolo di Distilled chiamato “What you can do with a free SEMrush account” perché penso sia un esempio geniale di native advertising. I miei complimenti al team di marketing di SEMrush. Naturalmente la mia è solo una supposizione che difficilmente verrà confermata, ma ti consiglio di leggere comunque;
Un’ottima guida base per il digital marketing
Seer Interactive ha pubblicato “Digital marketing guide for Nonprofits” una guida semplice ma chiara e, penso, potenzialmente molto utile per chi inizia da zero a fare digital marketing: anche se l’articolo è dedicato alle attività non-profit è un buon riassunto di quello che dovrebbe fare la maggior parte delle aziende locali che si avvicinano al digital marketing. Forse a te non serve, ma a qualcuno che conosci si: passaparola!
DuckDuckGo tra le possibili scelte per gli utenti europei per il motore di ricerca di default di Android
Zitto zitto, quatto quatto, DuckDuckGo si fa spazio su Android: secondo searchenginejournal.com, nell’ambito delle “attività di riparazione” riguardo la violazione delle norme antitrust per la quale l’Unione Europea ha multato Google per 5 miliardi di euro, il motore di ricerca privacy oriented sarà tra le possibili scelte quando Android sarà costretto a chiedere all’utente quale motore di ricerca voglia utilizzare.
Da quel che ho capito questo posizionamento molto interessante è stato ottenuto tramite una vera e propria asta fatta da Google durante la quale DuckDuckGo pare abbia investito davvero tanto, considerando che ad esempio Bing sarà tra le scelte solo in UK(e non penso che Microsoft potesse potenzialmente investire meno di DuckDuckGo, anche se a dirla tutta non so esattamente chi ci sia “dietro”). Trovi la lista completa dei risultati dell’asta per ogni paese dell’Unione Europea cliccando qui, in Italia troviamo anche il buon Qwant. News molto interessante, potenzialmente potrebbe avere un grosso impatto, ne riparliamo dopo l’estate.
Arriva puntuale il report di Google Maps sui TUOI spostamenti… si proprio i tuoi!
Hai ricevuto il simpatico report di Google Maps sui tuoi spostamenti nel 2019? Potrei trovarlo interessante e divertente se non sapessi che questi dati sono in mano a tantissime persone e soprattutto a AI che non vedono l’ora di trovare il modo di ottenere risorse a me molto care: tempo, attenzione, denaro (e quelle dei miei cari). Se ti sei perso questa email da Google Maps cercala: potresti rimanere sorpreso;
Ode (meritata!) a John Mueller
Mi è capitato di vedere un link verso una vecchia ode a John Mueller di Mariachiara Marsella data 2014 che personalmente condivido: John è bravo a interfacciarsi con il prossimo ed è dotato di una pazienza degna di un maestro Zen durante i suoi hangout su YouTube. Il problema sono i limiti di quello che può e non può dire e soprattutto quando deve fare “propaganda” per arginare problemi come lo spam. Anche se è dello scorso decennio (ora posso proprio dirlo!) il messaggio (parafrasando spero in modo corretto) del “non imporre la propria competenza” mi piaceva molto e ho voluto riportarla anche qui;
CFIUS vs TikTok ovvero ByteDance (fate leggere il titolo ad un over 70 se volete ridere)
Visto che siamo in tema, negli Stati Uniti l’argomento “Cina” è piuttosto caldo: dalle polemiche per la censura di contenuti relativi alle proteste di Hong Kong da parte di aziende americane (ne puoi leggere una lista qui) fino alla recente notizia di un’investigazione che è stata lanciata dal “Committee on Foreign Investment in the United States (CFIUS)” verso TikTok per la sua acquisizione di musical.ly.
Questo perché, e personalmente non lo sapevo, TikTok è di un’azienda cinese chiamata “ByteDance” e il pensiero che i dati di quasi 27 milioni di utenti americani attivi su di una piattaforma controllata proprio dalla Cina, poco sorprendentemente non piace molto a chi governa gli Stati Uniti. Se conoscete ragazzini (o “ragazzoni”) che frequentano la piattaforma fateglielo presente, forse non servirà a nulla ma almeno avrete provato a creare nuova consapevolezza.
Il pensiero della settimana
Quello che ci siamo lasciati alle spalle è stato uno degli ultimi decenni nei quali il mondo è stato “dominato” dagli Homo Sapiens, penso che facendo SEO ci renderemo conto prima di tantissimi altri che le nuove generazioni appartengono ad un’altra specie, forgiata a livello neurologico (ci sono degli studi a riguardo) dal rapporto simbiotico con la tecnologia ed Internet. Non si parla “solamente” di un’altra cultura, ci sono vere e proprie differenze biologiche.
Detto questo ho dedicato a fine anno un video piuttosto personale proprio ai giovani Sapiens, ma che penso possa essere interessante anche per i loro genitori, lo trovi qua: https://www.youtube.com/watch?v=tBRnRwrVhnE.
Per concludere voglio ringraziarti per avermi dedicato il tuo tempo leggendo fino a qui! Se è la prima volta che leggi questa newsletter e non vuoi perderti la prossima, se vuoi leggere le precedenti o più semplicemente vuoi dire la tua su quanto è stato detto non devi fare altro che scrollare ancora un pochino:
Grazie nuovamente per aver letto fin qui e ti auguro un buon proseguimento!