Ciao! Sapevi che la classificazione “classica” dell’intento di ricerca fu iideata da un ingegnere di Altavista (non sto scherzando) nel 2002? Io no! E questa è solo una delle cose fichissime contenute questa newsletter, la quale ti arriva solo ora causa K.O. da influenza del sottoscritto e i conseguenti ritardi che ho dovuto (e devo) affrontare. Detto questo ti auguro una buona lettura.
E’ arrivato il momento di superare i 3 classici archetipi dell’intento di ricerca?
Come riporta questo articolo di Kane Jamison in questo articolo esplicativo sul funzionamento del loro servizio, la classica tripartizione “navigazionale/informazionale/transazionale” dei cosiddetti intenti di ricerca pare sia stata utilizzata per la prima volta, e quindi di fatto coniata, proprio da un ingegnere di Altavista in questo whitepaper del 2002. Il documento è di per se interessante perché parla, di fatto, delle peculiarità che concernono la information retrieval applicata ai motori di ricerca e te ne consiglio la lettura.
Tornando all’articolo di Kane il testo parte evidenziando due problemi relativi a questo concetto con osservazioni che personalmente condivido:
- Sono 3 concetti troppo ampi e comprensivi nell’ambito di SERP che invece sfaccettano su molti più fronti l’intento di ricerca: se mi segui da un po’ sai che da anni ti dico di ragionare da chi l’utente voglia sentire la risposta ad una query, che tipologia di sito si aspetta (concetto che si ricollega con la riflessione sulle query syntax di AJ Kohn nella scorsa newsletter), che tipo di media preferisce per la fruizione della risposta e tanti altri;
- Molte ricerche comprendono contemporaneamente più di uno dei 3 classici intenti di ricerca: lui porta l’esempio di “amazon laptop deals”, una ricerca navigazionale, perché mirata ad Amazon, e nel contempo transazionale, perché vuole andare a pescare prodotti da acquistare;
Queste sono, secondo me, ottime riflessioni per nulla banali. Le prossime due che riporterò e commenterò sono una novità in questa newsletter perché… non sono d’accordo! Ma rimangono riflessioni interessanti:
- Secondo l’autore i SEO “bravi” in fase di keyword research classificano l’intenzione di ricerca delle query attraverso, appunto, la query stessa. Questo è un problema perché in realtà le query possono si avere dei “trigger” nella loro sintassi come quelli discussi da Kohn ma non sono per nulla affidabili. Penso che i SEO bravi se devono studiare centinaia di query… si guardano centinaia di SERP. Questo è quello che faccio, personalmente o con l’aiuto di persone fidate, perché l’intento si studia attraverso i risultati. Forse però non è così per molti e, come riporta l’autore, è effettivamente un problema. Dovendo fare la marketta al suo servizio secondo lui il problema specifico è che è stupido fare a mano qualcosa che può fare un tool ( ne dubito );
- Secondo l’autore i SEO non hanno necessità di comprendere l’intento di ricerca allo stesso modo nel quale i motori di ricerca lo comprendono: quello che dovrebbero fare è comprendere se il formato del contenuto è quello che Google vorrebbe servire. La trovo una visione molto miope e incentrata, di fatto, sul concetto che serve un tool, probabilmente il suo :). I SEO secondo me hanno assolutamente bisogno di studiare l’intento di ricerca che Google deduce dai dati da lui raccolti perché, oltre che permetterci di produrre del content che performi in modo ottimale sulle SERP, ci da accesso a tantissime informazioni importanti anche a livello di business, che deve essere sempre al centro di ogni azione nel marketing, qualsiasi sia il suo modello;
Ora non andrò nel dettaglio sul quale sia la sua proposta in termini di “nuove classificazioni per gli intenti di ricerca” perché mi interessava più che altro soffermarmi sulle premesse. Se vuoi il mio parere beh, personalmente trovo limitanti le 9 possibilità da lui citate ma mi rendo conto che per creare e vendere un tool non si possa dire ( ammettere ) che l’intento è MOLTO sfaccettato e sia meglio studiarlo “a mano”. Simpatica l’idea per lo “scoring” e mi ha fatto venire molta voglia di approfondire, e anche di molto, l’argomento. Per ora buona lettura (leggiti anche il whitepaper, non te ne pentirai!).
Ho scoperto che ora li chiamano “fraggles”
Avete presente quegli pseudo-sitelink dei quali vi ho parlato, tra le altre cose, la scorsa newsletter? Tipo questi:
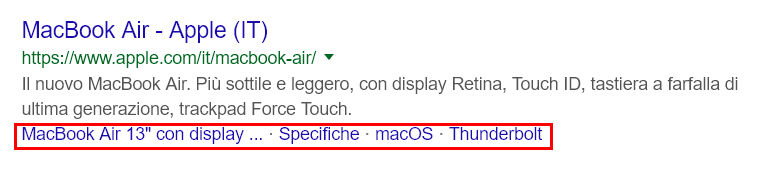
Sono link che possono ad esempio puntare a ID interni dei div della pagina tramite ancore, cercate ad esempio “seo immagini”, oppure possono puntare a pagine figlie della pagina in questione referenziate con link nella pagina stessa, provate a cercare “macbook air”. Nell’articolo che sto per presentarvi si parla addirittura (anche se non sono riuscito a ricreare il caso con le stesse query) di link in SERP che puntano a specifiche parti di un video.
Ebbene ho scoperto giusto oggi, leggendo l’articolo in questione, intitolato “What the heck are Fraggles?“, che oltreoceano li iniziano a chiamare appunto “fraggles” (almeno a quanto ho visto su Twitter!), ovvero la combinazione della parola “fragments“, frammenti, e “handles“, letteralmente le maniglie (o punti di ingresso, anche se in inglese con la parola handle si indicano più che altro le maniglie delle pentole o delle scatole, ma non fateci troppo caso). Il senso è riferirsi a qualcosa che sia il “punto di entrata (maniglie) verso un frammento di documento dalle SERP“. A dirla tutta l’autrice del post, Cindy Krum, diversifica i link verso le ancore, i classici “Passa a…” (se ben ricordo la traduzione) sotto la meta-description alle cosiddette fraggles ma personalmente mi riferirò, se vorrò usare questo termine, indistintamente a tutte e due le cose con lo stesso nome.
Mettendo da parte il neologismo la riflessioni interessante che vorrei riportarvi è che effettivamente la presenza, in varie forme, di questo genere di elementi in SERP porta a pensare che Google già da anni (l’autrice parla del 2017 ma io le ricordo anche nel 2014/2015). ma in modo più prominenete negli ultimi tempi, non solo analizza ma addirittura posiziona singole sezioni specifiche di documenti sul web.
L’autrice del post ipotizza che queste fraggles siano collegate intimamente al Knowledge Graph, perché di fatto si riferiscono a risposte molto specifiche che potrebbero, e da quello che dice lei sono, essere servite appunto una volta che il motore “evoca” la sapienza di tale contenitore per rispondere in modo diretto alle domande.
Molto interessante anche il riferimento a questa nuova tecnologia di Chrome che permette di mandare link a singole parole all’interno di un documento, già presente e attivabile per altro sulla versione Canary, la beta per intenderci. Di fatto si utilizza un parametro query come id al quale saltare: se ad esempio si vuole far arrivare l’utente alla parola Pippo sulla pagina topolinia.net/casi-sociali gli si manderà il link http://topolinia.net/casi-sociali/#targetText=Pippo.
Perché questo riferimento è interessante? Perché mi è capitato di vedere, come per l’autrice, che Google referenziasse punti specifici della pagina che non avessero un id al quale saltare come nei classici link in-page. Usando quasi esclusivamente Chrome non so se sia un comportamento replicato anche su altri browser, nota di demerito per me, ma a questo punto sarei curioso di testare. Forse, come fatto notare da altri prima di me, questa tecnologia potrebbe essere un primo passo verso il web senza URL (per renderlo più sicuro secondo loro, per renderlo meno accessibile da tecnologie diverse dalla loro secondo me, visto che anche Microsoft ha abbandonato Edge e costruirà un browser Chrome-based per Windows 10). Chissà che non sia una di quelle cose che cambierà Internet fino a renderla irriconoscibile e mi (ci) farà cambiare lavoro. Io già un anno fa davo 5 anni di vita a Internet come la conosciamo, ora sono 4!
Sembro un disco rotto ma… è un po’ che te lo dico: Google costruisce la sua “matematica del significato” in modo molto più approfondito e capillare di quanto probabilmente immagini: non solo perché analizza keywords e keyphrases ma perché arriva a “capire” quali sono i cluster che generano significato dentro le singole pagine e a studiare quanto le pagine di uno specifico sito e il sito stesso siano rilevanti per query più ampie studiando il funzionamento di questi cluster nel contesto di un’esperienza legata ai path per utenti e crawler. Sembra la supercazzola antani ma ti assicuro che non lo è, non per niente avrei dovuto fare un corso dedicato all’argomento (rimandato a data da destinarsi).Per concludere… mi piaceva di più pseudo-sitelink!
Leggi qui l’articolo di Cindy Krum sulle fraggles
E-A-T E’ UN FATTORE DI RANKING!!!… o forse la community è alla ricerca di titoloni
Nelle ultime ore sta girando con l’iperbolico titolo hype “GOOGLE AMMETTE CHE E-A-T E’ UN FATTORE DI RANKING IN UN WHITEPAPER!!!” un nutrito gruppo di articoli, tipo questo o questo, che fanno riferimento ad un whitepaper pubblicato pochi giorni fa nel quale Google parla in modo molto vago e molto poco tecnico di come si comporta riguardo le fake news e i contenuti YMYL (your money your life).
Il mio pensiero è in linea con quello del mitico Michael Martinez:
“(…) Il documento è molto vago ed ambiguo ed è stato scritto per migliorare l’immagine pubblica di Google nell’ambito del dibattito internazionale riferito a come la propaganda venga utilizzata per influenzare l’opinione delle persone attraverso la rete. Non è un tratta su come funzionano gli algoritmi di Google e non dovrebbe essere usato dai marketer come fonte di informazioni tecniche su quegli stessi algoritmi.” Amen.
Purtroppo la ricerca di sensazionalismi e di esposizione a tutti i costi (ad esempio quello molto caro della diffusione di disinformazione) colpiscono sempre più duramente la community a livello globale. Nel mio piccolo spero di portare la tua attenzione alle cose veramente importanti e interessanti. La lettura del blogpost di Google e del documento possono essere secondo me comunque interessanti a livello comunicativo, soprattutto se pensiamo al livello di consapevolezza che hanno i burocrati rispetto all’ecosistema della ricerca su Internet e delle sue tecnologie.
Perdonami il commento piuttosto duro ma per quanto mi riguarda informare significa anche mettere in guardia quando necessario. Un’ultima nota: i due siti che ho citato, Search Engine Roundtable e il blog di Marie Haynes non sono tra le mie fonti di informazioni preferite ma producono anche contenuti interessanti, non prendere questo commento come un giudizio sommario: si tratta di una riflessione sullo specifico articolo.
Altri articoli interessanti
Ecco una carrelata di articoli interessanti che non ho voluto/potuto approfondire e qualche curiosità che vorrei segnalarvi:
- Che meraviglia questo articolo sulle personas! Finalmente qualcuno, nello specifico il buon Anthony T. del quale non ho trovato il nome completo, ha rotto il velo dell’ipocrisia che ricopre questo sistema incredibilmente utile sulla carta ma incredibilmente scolastico e poco efficace nella sala riunioni del cliente. Le personas “classiche” vengono al 99% ignorate perché sono troppo, troppo involute rispetto a loro stesse, troppo astratte e concentrate su dettagli che sono utili più in teoria che in pratica. Leggete le semplici guideline per creare personas “action-oriented” e, se vi piace lo stile, c’è anche la marketta per comprare il template alla fine del post. Visto il post lo perdono!
- Questo articolo di David Amerland intitolato “The death of social networks“ è uno di quegli articoli che ti fa sentire piccolo piccolo, quasi traumatizzato dalla differenza nel saper vedere lontano, o almeno per me è stato così. Per me come per molti altri il fallimento di Google Plus è stata fonte di faccine piangenti e poco più, ma la lettura data da Amerland fa riflettere sul fatto che questo accadimento possa divenire uno dei passi che cambierà il rapporto della società con il mondo digitale, qualcosa che sarà parte di un cambiamento a livello storico, e non parlo solo di noi “marketer” o operatori del web, parlo dell’umanità intera. Fatti un grosso favore e leggilo con attenzione, non te ne pentirai. Non l’ho commentato perché devo prima pensarci su;
Il pensiero della settimana
Wow l’ultima settimana è stata davvero tosta, avrei voluto produrre molto di più ma non mi è stato fisicamente possibile, il mio corpo sta ancora pagando il troppo lavoro dell’ultimo trimestre dello scorso anno: ricordati sempre di rispettare te stesso e il tuo corpo e di non darti mai per scontato. Sembra un consiglio da “Cioè” ma te lo dico con la massima serietà… mentre finisco la newsletter alle 01:46. Meglio andare a dormire!