(Nota del 27/01/2020: lascio per ragioni di “archivio storico” la introduzione alla newsletter che era nel vecchio sito, che oggi ha poco senso a livello pratico ma mi dispiacerebbe cancellare, se sei interessato solo al vero e proprio contenuto della newsletter saltala pure!)
Ciao e benvenuto a questo nuovo esperimento di delivery della mia newsletter SEO: visto che i server di posta Gmail hanno deciso che le ultime 2 edizioni di questa rubrica sono state “promozioni”, mettendole nella infame cartella e di fatto nascondendo a chi non ha messo nella rubrica newsletter@emanuelevaccariweb.it le newsletter stesse, ho deciso di usare la mail vera e propria solamente come un semplice “tramite”, quasi una “notifica”.
Se hai perso le ultime due edizioni della newsletter ti consiglio di recuperarle qui (secondo chi le ha lette sono molto interessanti!):
- Un update per Google e uno per il copyright europeo: troppi update? – EV SEO Newsletter #37
- Cosa significano veramente le regole di Google per Google? – EV SEO Newsletter #38
Detto ciò questa 39° edizione della newsletter è solo “ospitata” temporaneamente su questo sito: verrà spostata su di un altro progetto al quale lavoro da settimane e del quale ti darò notizia non appena sarà pronto. La newsletter per altro diventa bisettimanale: questo perché
- le notizie/pubblicazioni interessanti stanno diventando sempre più rare (purtroppo);
- per darmi modo di pubblicare altri contenuti in altre forme (ad esempio finire i tanti podcast della nuova serie);
Un’altra cosa che voglio segnalarti è che effettivamente, come mi facevano notare alcuni ragazzi tra i quali il mitico Ilario Gobbi (che saluto visto che di solito è un lettore di questa rubrica!), alcuni passaggi delle newsletter in passato erano veri e propri articoli: per questo quando una trattazione si gonfierà a dismisura com’è stato per quella sugli operatori before: e after: ne farò direttamente un articolo sul blog. Li segnalerò nella newsletter di volta in volta ma puoi anche attivare le notifiche push, seguirmi su Twitter o frequentare EV Oasis o Fatti di SEO per non perderteli.
Direi che ora possiamo iniziare con la EVSEO newsletter #39!
Ho pubblicato un test sui nuovi operatori before: e after: di Google search
Come ho già accennato nelle scorse settimane ho pubblicato un test piuttosto approfondito (per quanto mi risulti l’unico al mondo!) sui nuovi operatori before: e after: di Google.
Mi fa un po’ strano mandare il link praticamente “alla porta accanto” del blog ma li si trova e li ti invito a leggere nel caso fossi interessato (e dovresti esserlo!). Colgo l’occasione per ringraziare i ragazzi che mi hanno riportato le loro esperienze a riguardo: alcune cose le integrerò in un aggiornamento dell’articolo che vorrei fare tra qualche mese.
Personalmente mi ritrovo a usare spesso questo operatori e, grazie ai test, lo faccio con più consapevolezza e dando il giusto peso ai risultati, facendo molto spesso anche delle “controprove” visto il comportamento incostante degli operatori stessi. Mi piacerebbe fare un video o un approfondimento parlando degli utilizzi pratici degli operatori stessi, se me ne volete segnalare qualcuno commentate o scrivetemi, in palio citazioni e link per quelli che verranno inclusi e quindi menzionati!
Sto scrivendo un articolo su Google Discover
Sto preparando un articolo su Google Discover ma Google stessa continua ad annunciare o rilasciare feature (ad esempio il rilascio delle ads dentro a Discover) e anche io continuo a notare nuovi comportamenti.
Discover è molto interessante perché è un traffic driver veramente potente (ricordo un interessante studio sulla ripartizione tra le origini di traffico referral nel 2018, che purtroppo dopo mezz’ora di ricerca non riesco a trovare, che dava Discover come in costante crescita) trattandosi di fatto un feed personalizzato inserito in un momento molto particolare dell’esperienza utente, ovvero all’inizio di un momento “di curiosità” se così si può dire. Io stesso mi trovo ad utilizzarlo molto spesso. Sarei molto curioso di sentire le tue esperienze a riguardo.
La mia intenzione è quella di farvi leggere il mio “pseudo-studio” a riguardo il prima possibile. Se hai considerazioni o esperienze da condividere con me questo è un buon momento per prenderti un bel link dal mio blog: nel caso il tuo contributo venisse inserito nell’articolo un link ci scappa al 100%. Attendo tue!
John Mueller parla del rapporto tra contenuto “nascosto” dietro tab e gli snippet sulle SERP
Questo è un argomento che voglio assolutamente affrontare in un podcast ma, visto che John Mueller ha fatto una dichiarazione interessane a riguardo in questo Google Webmaster Central hangout, parliamo di tabbed content (non so se si possa declinare in questo modo ma… l’ho fatto!), per intenderci questa roba qui:
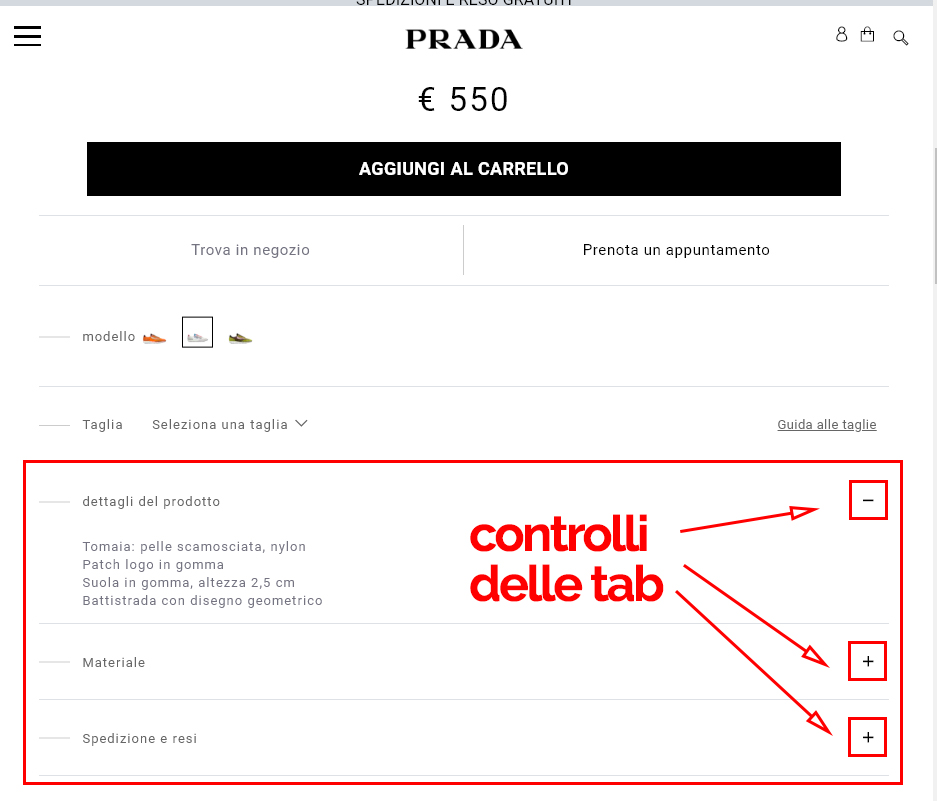
Trovi evidenziate in rosso le “tab” presenti in un prodotto sul sito di Prada
Rispondendo ad un ragazzo che lamentava il fatto che il suo contenuto “nascosto” dietro tab non apparisse negli snippet in SERP il buon John Mueller ha dichiarato (traducendo e parafrasando) che:
Il contenuto “dietro” le tab lo utilizziamo per l’indicizzazione e il posizionamento, soprattutto quando lo analizziamo nella versione mobile con il mobile first indexing. In questo senso non dovrebbe essere mai un problema ma non lo mostreremo nello snippet: questo perché se mostriamo all’utente del contenuto nello snippet gli stiamo “promettendo” che ritroverà questo contenuto nella pagina di atterraggio e, se sappiamo che viene nascosto di default dietro una tab, non vogliamo rimanga deluso non trovandolo nella pagina.
Nella discussione su Twitter “lanciata” da Glenn Gabe, dalla quale ho scoperto la dichiarazione di Mueller che sto commentando emergono alcune questioni interessanti:
- Un utente lamenta che cercando una stringa specifica di testo nascosta dietro tab e limitando la ricerca con l’operatore “site:” Google non ritorni nulla;
- Un altro si preoccupa che una manipolazione via Javascript che manipola il CSS facendo apparire una parte di contenuto solo quando questo viene visualizzato nel viewport del browser che visita la pagina possa quindi interferire con gli snippet;
Mueller, come al solito, rimane piuttosto vago.
Io però voglio condividere con te una mia personale regola molto, molto semplice e chiara che mi ha dato tante soddisfazioni: se vuoi veramente che un contenuto sia considerato da Google e dagli utenti mettilo “in chiaro” e più in generale “falla semplice”. Niente tab, animazioni, sequenze mistiche o trasformazioni multicolore tipo Dragon Ball: inserisci il contenuto in modo che sia semplicemente già stampato e visibile quando l’utente lo raggiunge semplicemente scrollando la pagina.
Google valuta in modo più raffinato di quello che pensi gli elementi della pagina stessa: è stato dichiarato più volte, sia in documenti tecnici che da Googler, che elementi quali la tipografia e il posizionamento in termini di pixel dei contenuti all’interno della pagina influenzino il grado di importanza che Google assegna a specifici elementi della pagina stessa.
E’ un discorso troppo lungo da affrontare nel dettaglio in una newsletter ma voglio farti una semplice domanda, ovvero secondo te:
- un link dello stesso colore del testo e senza sottolineatura;
- uno posizionato dentro un box di un colore completamente diverso dalla sfondo con un font grande 4 volte quello del testo;
hanno la stessa importanza per chi ha creato la pagina, che evidentemente vuole mettere in evidenza il secondo, e per chi la legge, che con ogni probabilità avrà la sua attenzione attirata sempre dal secondo caso? Secondo me no.
Questo naturalmente non significa che i link vanno tutti in bold con colori sgargianti e le parole chiave sottolineate con un font size maggiore del resto del testo: significa che Google è abbastanza “furbo” e raffinato da capire queste nuance (che proprio tali non sono) nei testi e più in generale nelle pagine e “comportarsi” di conseguenza a livello di analisi e di valutazione degli elementi delle pagine che va ad indicizzare.
In buona sostanza nascondi un contenuto dietro una tab significa che anche per te questo contenuto non è così importante che venga visto. Se lo è ti consiglio di riflettere sulla tua scelta di utilizzare la tab stessa. Ricordati sempre che buona parte dei tuoi utenti fatica a capire che può continuare a leggere una pagina scrollando (te lo dico per esperienza), figuriamoci utilizzare un piccolo segno grafico per aprire una tab o un accordion. Gli utenti visitano, vivono ed esperiscono il web in modo molto differente da qualcuno che ci lavora come probabilmente fai te se stai leggendo questa newsletter.
Le tab vanno di moda ne più ne meno del menu hamburger, sono gettonatissime dai web designer ma all’atto pratico non funzionano molto bene. Sul menu hamburger feci un podcast che, se non hai ascoltato (o letto), ti consiglio di recuperare: lo trovi in questa pagina.
Un chiarimento su come determinare qual è la pagina canonica che Google prende in considerazione per un risultato di ricerca
Qualche giorno fa il mio amico Walid Gabteni mi ha fatto notare che Google ha tolto l’operatore “info:” dalle SERP di Google, annunciandolo (in sordina) in questo post pubblicato sul Webmaster central blog . Personalmente (sbagliando) non lo usavo moltissimo ma era piuttosto interessante soprattutto qualche anno fa quando ritornava queste cosine qua:
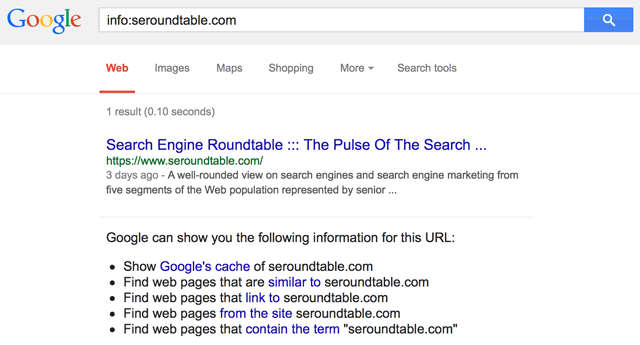
Ecco l’operatore info in azione prima del 2018. Screenshot preso da un articolo di Search Engine Land
Interessante no? Troppo tardi! Questa notizia è venuta fuori, come hai potuto già notare se hai letto l’articolo di Google del quale ho messo il link, parlando di come determinare quale sia l’URL canonico scelto da Google per una pagina. Non sto parlando di controllare quale sia quello specificato a codice nel tag canonical ma di quello effettivamente scelto da Google.
Come giustamente fa notare la pagina ufficiale di supporto relativa agli URL canonici esistono infatti diversi casi problematici dove l’URL determinato come canonico (anche cross-domain, ovvero tra due domini differenti) differisce da quello che desideriamo (e a volte specifichiamo), ad esempio quando sbagliamo la sintassi del codice o viene iniettato codice malevolo senza che ce ne rendiamo conto.
Durante un Webmaster Central office-hours hangout il buon John, rispondendo ad una domanda (piuttosto criptica) di un utente relativa proprio alle alternative all’operatore “info:” per confermare l’URL canonica dopo il trasferimento di un sito , ripete (aggiungendo qualcosina) quanto scritto nell’articolo del blog di Google:
- l’operatore “info:” non funziona più e quindi non si può vedere l’URL canonico da li;
- l’unico tool che riporta in modo 100% corretto l’URL canonico scelto da Google è quello chiamato “URL inspection tool/Controllo URL” della nuova Search Console:
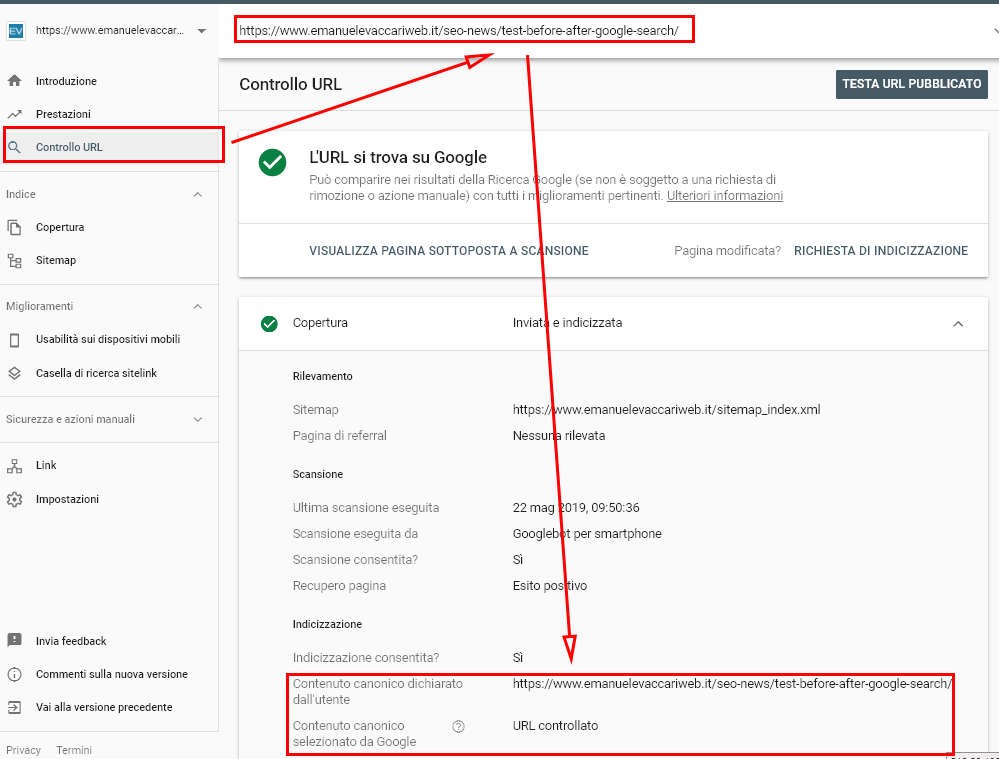

- Gli operatori “site:” e “inurl:” non mostrano l’URL canonico perché, di fatto, forzano risultati riguardanti le URL o i domini specificati nel caso di “site:“. Non fare affidamento a questi operatori per capire quale sia la pagina canonica;
- E’ possibile che chiamando la cache di Google su di un URL Google mostri un’altra pagina rispetto a quella presente all’URL della quale la si richiama: quella che ha effettivamente scelto come canonica;
Qua non ho molto da aggiungere: il (relativamente) nuovo tool della Search Console è probabilmente la novità più interessante e vi consiglio di usarlo non solo per vedere la pagina canonica. E’ uno di quei casi dove mi fido di John.
Alcuni “tool” veramente utili che non dimenticherete dopo un paio di utilizzi: i bookmarklet per Chrome
C’è la mania tra i colleghi di fare raccolte infinite di tool che, pur risultando simpatici ad un primo utilizzo, vengono puntualmente dimenticati dopo i primi test. La realtà è che il nostro tempo è prezioso e tendiamo a servirci dell’essenziale (e del gratuito!). Ebbene i tool che sto per presentarti, che proprio “strumenti” (la traduzione letterale di “tools”) nel senso stretto del termine forse non sono, servono essenzialmente per non farti perdere tempo e penso che quando li avrai provati difficilmente potrai dimenticartene (anche perché di solito vengono parcheggiati in un posto molto in vista, ci arrivo).
Venendo al dunque dopo questa introduzione che ti ha fatto… perdere tempo ecco questo articolo molto interessante di Glen Allsopp dove viene presentata una serie di bookmarklet SEO oriented per Chrome. Per farla molto breve un bookmarklet non è altro che un bookmark che esegue codice javascript quando viene invocato. Di fatto sono “mini applicazioni” da utilizzare cliccando sul bookmark stesso ad esempio sulla barra dei preferiti.
Per crearne uno non devi fare altro che:
- Cliccare col tasto destro del mouse sulla barra dei preferiti;
- Selezionare “Aggiungi pagina”;
- Incollare il codice del bookmarklet nel campo “URL”;
- Inserire un nome nel campo omonimo (o puoi non farlo se come me utilizzi la singola icona);
Per intenderci eccone uno nel mio browser:
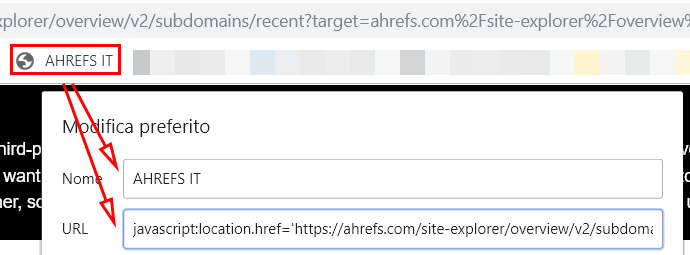
L’autore del post ne presenta una serie piuttosto interessante:
- Un bookmarklet per lanciare una query complessa su Google che ricerca specifiche stringhe all’interno del dominio del sito che stiamo visitando;
- Un bookmarklet dove specificare una query che verrà inviata a diversi siti contemporaneamente aprendo tab multiple (nell’esempio su Google Trends, Ubersuggest e Wordtracker);
- Diversi bookmarklet per aprire tool di terze parti preferiti analizzando il dominio del sito che si sta navigando. Si può utilizzare con qualsiasi tool che utilizzi parametri query, come ad esempio Ahrefs, Majestic, Moz, SEMRush, archive.org, lo structured data testing tool, Google PageSpeed insights );
- Un bookmarklet per estrarre fino a 100 URL della SERP di Google che stiamo visitando (attenzione: questo codice estrae brute force ogni link sulla pagina, ad esempio anche i sitelink, ogni singolo video di un carosello di video e altri comportamenti da studiare prima i prendere per buoni i dati);
- Un bookmarklet per evidenziare tutti i link nofollow nella pagina;
Per quanto molti di questi personalmente li avessi già visti, in forme più o meno raffinate di queste, temo che molti miei lettori non abbiano neanche mai visto un bookmarklet ed è un peccato. In tutta sincerità anche per me è stata l’occasione di raffinare un pochino alcuni passaggi base nell’analisi di siti e pagine web.
Questo articolo mi ha ispirato e vorrei preparare alcuni bookmarklet “originali” made by Vaccari ma intanto vi lascio con una cosina che ho creato al volo, scopiazzando quelli dell’articolo, per aprire AHREFS e SemRush su di un dominio da digitare una volta lanciato il bookmarklet:
javascript:(function() { new Promise(setQuery => { var input = window.prompt('Enter your query:'); if (input) setQuery(input); }).then(query => { window.open('https://ahrefs.com/site-explorer/overview/v2/subdomains/recent?target=' + query ); window.open('https://www.semrush.com/it/info/' + query );});})();
Se il bookmarklet non pare funzionare controlla di non aver scordato la chiusura di funzioni controllando con un syntax highlighter, ovvero un sistema che ti controlli la sintassi del codice (per Javascript, PHP, HTML e tutti gli altri linguaggi/markup puoi usare molto semplicemente Notepad++).
Attenzione: come specificato nell’articolo questi bookmarklet che aprono più tab vengono visti come popup da Chrome! Per evitare che vengano nascoste delle finestre dovrai specificare che il sito possa aprire popup nella barra degli indirizzi.
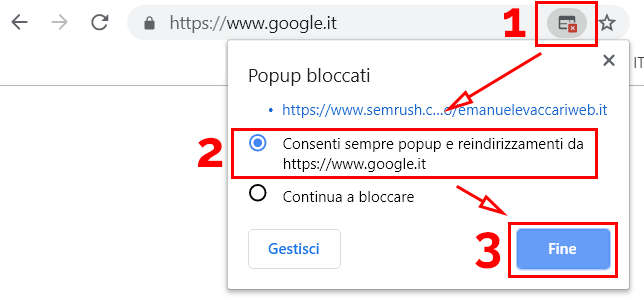
Questo purtroppo va fatto per ogni sito dal quale lanciato questo tipo di bookmarklet. Per aggirare il problema ti basterà lanciarlo sempre dopo aver aperto ad esempio google.it, pagina dove immagino capiterai molto spesso (nota: non funziona aprendo una nuova tab da Chrome perché è una pagina “speciale” e non una vera e propria pagina web).
Se già usavi questo tipo di soluzione e vuoi segnalare qualcosa di tuo che può essere utile per i lettori scrivi un commento o una email e lo integrerò/segnalerò quando farò l’articolo dedicato!
Altri articoli interessanti
Ecco una carrellata di articoli interessanti che non ho voluto/potuto approfondire e qualche curiosità che vorrei segnalarti:
- Il buon Ruben Vezzoli ha pubblicato un articolo molto pratico sull’utilizzo dei dati di Search Console su Data Studio, con alcuni esempi pratici di analisi facilmente automatizzabili, come la rilevazione delle keyword uniche o la distinzione tra traffico brand e non brand. Questo mi fa pensare che non ho mai fatto la parte due del mio template di Data Studio dove facevo una cosa molto simile (anche se in modo molto meno raffinato): sono uno scandalo. Per ora godetevi questo articolo di Ruben, io lo metto nella lista delle cose da fare nelle prossime settimane.
- Nel caso vi fosse servita una conferma le chiamate AJAX/XHR consumano il crawl budget del vostro sito: grazie al mitico AJ Kohn il caro Gary Illyes ha ufficialmente dichiarato la cosa via Twitter, andando ad aggiornare un post ufficiale dedicato proprio al crawl budget sul blog di Google che, se non ti sei mai letto, ti consiglio di leggere;
- Ricordi quando ti avevo detto che il (bellissimo) film “Her” del 2013 ha immaginato 6 anni fa l’interfaccia con la quale avremo a che fare tra 4/5 anni? Un pezzetto di questo futuro è stato presentato al Google I/O (che devo ancora finire di “spulciare”) tramite l’annuncio di Duplex for Web: si potrà chiedere a Google di prenotare per noi qualcosa via web in modo totalmente automatizzato. L’assistente virtuale farà tutti i passaggi automaticamente, dall’accedere al sito a compilare i form. Questo sistema non richiede nessuna implementazione sul sito che “riceve” la visita della A.I. Naturalmente cose quali, ad esempio, le informazioni riguardanti il perché l’assistente dovrebbe consigliare una prenotazione e cosa scelga (o consigli) di prenotare vengono dall’analisi di tutti i nostri dati sensibili come al solito preda della A.I. di Google. Questa tecnologia è affascinante ma Google diventa sempre più sfacciata nell’invasione della nostra privacy (o presunta tale). Traducendo letteralmente un tweet di Sundar Pichai, CEO di Google:
Ci stiamo trasformando da un’azienda che ti aiuta a cercare le risposte ad una che ti aiuta a far si che le cose vengano fatte… vogliamo che i nostri prodotti lavorino duramente per te, nel contesto del tuo lavoro, della tua casa e in generale della tua vita. Ogni prodotto condivide lo stesso obiettivo: essere d’aiuto.
Lascio a te riflettere sul fatto che sia una cosa buona o meno;
- Sempre a Google I/O è stato annunciato che Googlebot passerà dall’ormai datato Chromium 42 a Chromium 74, quello attuale, e lo terrà aggiornato con la release di Chromium nei browser utente. Sorprendentemente non ne ha parlato praticamente nessuno nella community SEO italiana, anche si tratta di una svolta che definirei epocale: Googlebot, semplificando moltissimo, acquisisce una serie molto lunga di “migliorie” ed è in grado di interpretare le pagine in un modo molto più simile a quello del Chrome che molti di noi utilizzano ogni giorno. Dico “simile” perché rimangono, come indicato nel post stesso, una serie di problemi legati all’interpretazione di Javascript. Non ho trovato una lista di comparazione delle nuove features e non ho avuto tempo di farla, per questo relego per ora la questione ad un punto “non esplorato” della newsletter. Detto questo, per chi non lo conoscesse già, consiglio la lettura di questa guida di Google al Lazy Loading, indicata da Google stessa nel post su Googlebot evergreen (che rimane, come già detto, aggiornato alla versione “montata” nei browser utente). Molto probabilmente tornerò sull’argomento in modo più approfondito;
Il pensiero della settimana [lungo ma importante… suona male vero?]
Le ultime settimane sono state veramente impegnative:
- tanti lavori importanti per clienti ancora più importanti (e pazienti);
- la mia partecipazione al mitico SeriousMonkey di Enrico Altavilla come relatore, per la quale ho ricevuto feedback molto positivi che mi riempiono di soddisfazione (della quale vorrei fare un report) e della quale ringrazio Enrico Altavilla che ha organizzato qualcosa di veramente differente, interessante e l’ha gestito come un signore, dall’inizio alla fine;
- la messa in cantiere di tantissime novità riguardo il mio sforzo divulgativo (ad esempio il rilancio del podcast, che vorrei ripartisse già la settimana prossima tempo permettendo, e il beta testing del Patreon, con i santi che ancora mi supportano e sopportano);
In queste settimane inoltre ho avuto modo di “fare due conti”, cercando di capire il mio impatto sulla community SEO italiana. In buona sostanza:
- ho prodotto sul mio blog articoli originali, traduzioni di articoli con approfondimenti (e un sistema di attribuzione verso l’autore originale così chiaro che mi è valso il plauso dei colleghi d’oltreoceano), guide e test SEO sempre senza fuffa, senza mai “parlare per dare aria alla bocca” e mai scritti per vendere nulla, il tutto visualizzato letteralmente centinaia di volte al giorno con feedback positivi e ringraziamenti continui;
- ho scritto 39 newsletter piene di approfondimenti con centinaia di lettori (ma traditi dai server di posta) e diversi “oh ma quando esce quella nuova?” che mi riempiono di orgoglio;
- ho registrato 38 video che hanno fatto investire 86 giorni (!!!) ai miei spettatori nell’essere guardati su Youtube;
- ho registrato 28 podcast di iper-nicchia SEO ascoltati più di 10mila volte (qua non ho purtroppo il dato dei minuti);
- ho investito innumerevoli ore o più probabilmente giorni della mia vita nella community SEO, in buona parte sui mitici Fatti di SEO, rispondendo alle domande di chiunque mi chiedesse (con gentilezza) qualcosa sulla SEO;
Ho fatto tutto questo praticamente da solo (salvo la produzione tecnica degli ultimi elementi audio e video, pagata di tasca mia per produrre di più), lo dico con orgoglio, investendo il mio tempo e mettendoci letteralmente tutto me stesso, rinunciando spesso al sonno (anche ora che scrivo sono le 03:32 di un venerdì notte) perché oltre tutto questo devo naturalmente lavorare. Per i più maliziosi colgo l’occasione per ribadire che il tempo per fare queste cose si trova facendo sacrifici, non smettendo di lavorare.
Detto questo circa un mese fa ho deciso, in barba al fatto che probabilmente avrà un impatto negativo sulle singole piattaforme di distribuzione, di raccogliere tutti i contenuti che ho prodotto in un unico contenitore in modo che siano catalogati e liberamente consultabili da chiunque. Un puzzle che di fatto diventerà, o almeno cercherò di far diventare, un punto di riferimento per la community SEO italiana e non, fatto di contenuti senza l’ombra di interessi diversi dalla divulgazione e senza fuffa. Un progetto che porta anche “la firma” di quella santa della mia ragazza che mi ha aiutato, nelle sue pause pranzo, a trasportare tutti i contenuti in questa nuova piattaforma. Grazie Elisa.
So già che purtroppo, nonostante tutto, tanti colleghi continueranno a fare finta che non esisto, evitando di citarmi anche a scapito del fatto che un mio contenuto possa essere utile ai loro eventuali interlocutori. Continuerò a non essere mai citato nelle liste di esperti e divulgatori e continuerò a vedere tristi video dove si abbozza qualcosa che ho detto in un commento il giorno prima. I motivi sono molteplici ma sono tutti talmente tristi che mi vergogno per queste persone nel citarli, e quindi non lo farò. A questi “colleghi”, che probabilmente stanno leggendo queste righe, vorrei dire chiaramente che ho affrontato e sconfitto cose molto peggiori nella mia vita. L’unico modo che avete per tenermi testa è rimboccarvi le maniche e produrre. Io continuerò nonostante tutto a citare anche la persona che mi tratta peggio se produrrà qualcosa di utile per chi mi legge, mi ascolta o mi guarda. Ai (tanti, anche questo lo dico con orgoglio) che mi sostengono invece dico grazie: siete uno dei motivi che mi spinge a perseverare nonostante il vento (piuttosto puzzolente) avverso.
Finita questa simpatica parentesi per questa settimana è tutto: se hai avuto il coraggio di leggere fin qua e non vuoi perderti la prossima newsletter puoi iscriverti utilizzando il form qui sotto (ricordati di mettere newsletter@emanuelevaccariweb.it in rubrica per evitare che finisca nella cartella promozioni di Gmail!):
Io per ora ti ringrazio nuovamente per aver letto fin qui e ti auguro un buon proseguimento!