- Google, secondo diversi webmaster e colleghi, ha rilasciato un update tra il 7 e il 9 di febbraio (con un presunto roll-back la settimana successiva): analizziamo la situazione e utilizziamola come scusa per parlare di crawling e indicizzazione;
- News riguardanti strani test di Google sulle SERP, il nuovo “pannello Review Schema” sulla Search Console, LaserTagger, il nuovo limite in kb per i CSS di AMP, 4 cose da sapere sull’implementazione di Schema che non trovi nella documentazione, come Google potrebbe posizionare i podcast;
- Tools per fare il debug di un sito tramite CSS, un bookmarklet per confrontare un sito con e senza JS, un generatore di FAQ Page Schema, una fantastica raccolta di Regex per la SEO;
Questa settimana ho letto, analizzato e valutato 116 tra articoli, video, podcast e in generale contenuti SEO
Ciao e benvenuto alla edizione #48 della EV SEO newsletter, nella quale ho raccolto le novità e i contenuti SEO più interessanti che ho letto e selezionato per te tra l’8 e il 15 febbraio 2020. Buona lettura!
Parliamo di crawling attraverso il Google update senza nome di inizio febbraio
Barry Schwarz ha riassunto su seroundtable.com le notizie e le indiscrezioni raccolte da vari colleghi riguardo un possibile nuovo update di Google in rollout, con diverse persone che su Twitter hanno riportato di cambiamenti anche molto consistenti, nell’ordine del 10/15/20%, già dal weekend dell’8 e 9 febbraio.
SemRush e altri provider hanno escluso che si tratti di un “contraccolpo” sui loro sistemi dovuto all’update dei featured snippet, il quale ha sicuramente avuto un impatto molto forte sui loro database avendo “mosso” milioni di SERP in un lasso di tempo piuttosto limitato.
Personalmente mentre scrivo queste prime righe (11 febbraio 2020) non ho ancora notato nulla né su siti piccoli né su quelli (anche molto) grandi per i quali faccio SEO in Italia.
Leggendo le discussioni sui forum segnalate da Schwartz nel suo post ho notato una cosa: molti utenti segnalano diversi fenomeni anomali relativi all’indicizzazione. Due esempi su tutti:
- totali de-indicizzazioni di siti (che però sono discusse su di un forum dove ci si confronta su come fare spam… chi vuole intendere intenda);
- l’aumentare improvviso e apparentemente immotivato delle pagine indicizzate;
Glenn Gabe ha notato un certo andirivieni del traffico, ora su ora, di un sito apparentemente colpito, per intenderci guarda questo suo grafico che fa un confronto con la settimana precedente:
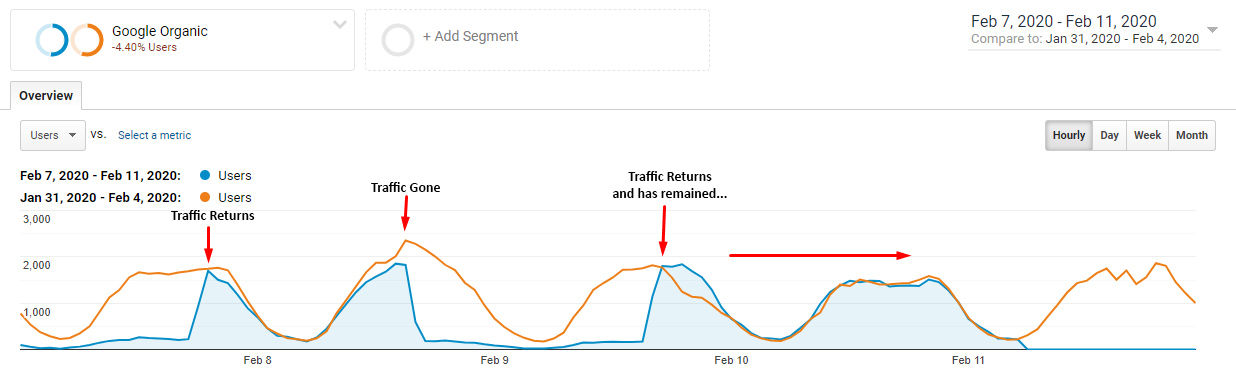
Personalmente, come ho già accennato più volte nelle community, ho visto anche io, su praticamente ogni sito per il quale abbia analizzato server log e Search Console da ottobre 2019, l’emergere di una particolare tendenza: Googlebot è diventato molto più “curioso” e invadente! Gli ho visto testare:
- filtri e query strings non accessibili direttamente dall’interfaccia, di fatto come su un utente si mettesse a testarli nella barra degli indirizzi;
- sitemap tolte dalla Search Console ma ancora caricate nello spazio web;
- vecchie URL non più in struttura anche da diversi anni (già visto e rivisto ma l’ho visto più del solito, e su URL molto vecchie);
Che questo sia collegato a questo update non posso confermarlo ma è qualcosa da tenere sotto controllo per il tempismo quantomeno “sospetto”. Ad esempio ho compiuto grandi pulizie sul crawling di un sito molto grande con risultati molto interessanti sia a livello di traffico che di conversioni su ads (probabilmente per le pubblicità tematicamente più forti) e con tempistiche che coincidono con questo update:
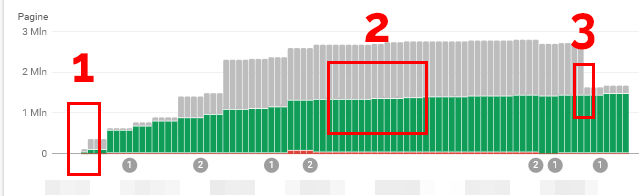
Per intenderci nei punti si possono osservare:
- Nel punto 1 viene effettuato il passaggio in HTTPS della piattaforma in contemporanea con la cancellazione di decine di migliaia di pagine con conseguente “deep crawl” da parte di Google nei giorni successivi, effettuato a parità (presunta) di crawl budget su di un numero molto ridotto di pagine totali segnalate attraverso sitemap e in genere raggiungibili attraverso la struttura/interfaccia del sito;
- Tra il punto 1 e il punto 2 Googlebot si da alla pazza gioia e scopre:
- un bug che generava in modo ricorsivo decine di migliaia di pagine duplicate: era presente da anni probabilmente ma Googlebot non ci era mai arrivato;
- decine di migliaia di pagine che prima il crawler non raggiungeva in quanto utilizzava il proprio budget di crawl su pagine ora cancellate;
- decine di migliaia di duplicati generati da bug nella gestione dei caratteri speciali, ad esempio gli spazi, nelle URL che prima Googlebot non raggiungeva e che non hanno nessun riferimento in struttura: li ha probabilmente “trovati” il crawler testando lui stesso la sostituzione dei caratteri nelle URL!
- decine di migliaia di pagine generate dagli utenti senza alcun riferimento in struttura (ad esempio le ricerche interne ed i filtri con input testuale);
- Nel punto 2 diagnostichiamo questi problemi, i quali vengono risolti correggendo i bug nel codice e utilizzando redirect 301 o mandando un header 404 a seconda delle necessità (e di cosa è stato, in ogni istanza, meglio fare per correggere il tiro;
- Nel punto 3, che si attesta nel periodo di questo fantomatico update, scompaiono dalla Search Console quasi un milione di pagine tra quelle “scoperte” dal crawler in questo nuovo corso di eventi;
Io ho sempre detto che questi grossi update di Google vanno a lavorare sul concetto di qualità, sia a livello di pagina che a livello di sito nella sua interezza, ovvero la “qualità media dei contenuti” della quale parlo in questa SEOttimana. La qualità naturalmente viene percepita rispetto a quello che Google può arrivare a “vedere”, ovvero a scansionare, fatto che passa inevitabilmente da come viene gestito il crawling sul sito.
Il 13 febbraio Google, attraverso il solito Danny Sullivan, ha commentato così una domanda diretta di un utente:
Facciamo aggiornamenti di continuo. Vi consiglio di rileggere i nostri consigli generali a riguardo (…)
Segue il link al solito Twitter thread dove si dice, in buona sostanza, che se Google non annuncia l’update descrivendo azioni da compiere semplicemente non ci sono particolari azioni da compiere e bisogna curare la qualità della propria offerta di contenuto.
Glenn Gabe, arrivando con qualche anno di ritardo rispetto alla mia SEOttimana (quando ci sta, ci sta!) ha scritto un articolo che descrive un concetto a me molto caro (e che ripeto da un bel po’): Google dovrebbe idealmente poter indicizzare solo le pagine veramente utili/importanti, fatto confermato (più o meno) da John Mueller durante questo video e questo video (link presi dall’articolo di Gabe).
Inoltre, aggiungo io, non bisogna far perdere tempo a Google evitando quanto più possibile di fargli scansionare pagine di scarso valore per l’utente. Su questo principio, che io chiamo “principio di affidabilità“, sto scrivendo un contenuto dedicato che condividerò attraverso questa newsletter non appena sarà pronto.
Gabe accenna a qualcosa di simile ma dice che per piccoli siti “il crawl budget non rappresenta un problema“, cosa che dissento nel modo più assoluto perché il problema sta nelle proporzioni tra parti del sito utili e parti inutili scansionate e non nel volume assoluto delle stesse. Un sito di 20 pagine con 10 pagine inutili ha un problema molto simile ad un sito con 20 milioni di pagine delle quali 10 inutili (dico molto simile perché anche se il problema, preso da se, è lo stesso, un sito con 20 milioni di pagine lavora su di un altra magnitudine di complessità).
Aggiungo anche che proprio per il bizzarro comportamento di Googlebot degli ultimi mesi vale ancora di più una considerazione che faccio da molto tempo: ricordati che Google difficilmente dimentica una pagina o un filtro/query string/modificatore che ha incontrato:
- se vuoi che qualcosa non sia visto da Googlebot e da utenti non autorizzati mettilo dietro password;
- se vuoi che qualcosa non sia visto da Googlebot ma sia disponibile agli utenti blocca con robots.txt da prima della creazione della pagina e metti comunque un noindex nel meta robots nel caso il crawler abbia l’idea di “buttarsi” sulla pagina;
Detto questo interessante la strategia di aggiungere (su siti che utilizzano una struttura delle URL con le cartelle, quella che descrivo in questo podcast) delle proprietà in Search Console relative alle singole cartelle in modo da vedere se alcune di esse hanno proporzioni anomale tra contenuti indicizzati, impressioni e click in entrata.
Attenzione: naturalmente questo richiede a monte che il sito sia ben strutturato sia tecnicamente che nelle sue logiche di categorizzazione/clusterizzazione del contenuto attraverso le cartelle prese in considerazione.
Solitamente considerazioni di questo tipo le faccio attraverso l’analisi dei dati di Google Analytics (o software di web analytics similari), ma questo è l’argomento di un altro contenuto… Per altro è possibile farlo in real-time attraverso Google Data Studio, ma anche questa è un’altra storia (se ti interessa approfondire lasciami un commento qui sul sito!).
Per altro, sempre riportato da un Gabe davvero scatenato questa settimana, John Mueller ha confermato un’altra cosa che dico da tanto tempo e che “correggo” praticamente durante ogni consulenza: bisogna, per quanto possibile, strutturare una gerarchia delle pagine dei singoli siti web, perché di fatto è il modo più chiaro che si ha per definire quali pagine rappresentano il sito e formano il suo “significato principale”, andando ad influenzare quindi le prestazioni di tutto il sito sulle singole query.
Detto tutto questo il 13 febbraio, come indicato da questo articolo su seoclarity.net sui “winners and losers” dell’update, Google sembrerebbe aver compiuto un rollback dell’update stesso, con alcuni dei siti impattati negativamente che sono ritornati esattamente alle posizioni precedenti.
Tutto finito quindi? Non proprio! Il fatto che un sito sia stato colpito da un update come questo significa che si trova in una situazione border-line e che c’è bisogno di analizzare la situazione il più presto possibile.
Dev’essere la classica “sveglia” di accezione romanesca che… ti sveglia. Piuttosto chiaro no? Fammi sapere se hai osservato qualche strano movimento!
EDIT: L’altro giorno nel mio feed di Facebook è apparso il post di un utente (che se si legge e ha piacere di essere identificato può contattarmi in privato per farmelo fare!) che parlava di una petizione fatta da diversi webmaster colpiti dal fenomeno del de-indexing i quali, coalizzati, hanno presentato il loro caso a John Mueller e si sono fatti “mettere a posto” l’indicizzazione. Trovi maggiori informazioni in questo post di seotool.ee.
Altre news sulla SEO
Segnalati dei test di SERP relative a query ad intento “transazionale” (voglio comprare XXX) con nuovi snippet “Google Discover style”
Un articolo di localseoguide.com (che ho scoperto tramite un tweet di Glenn Gabe) contiene un paio di video interessanti riguardanti test di Google su SERP desktop di query storicamente rivolte agli ecommerce (“mattresses” e “tvs“) che presentano però snippet con link verso contenuti “da blog” (che non vendono ma informano) presentati nello stile di Google Discover. Per capire bene cosa intendo ecco un esempio presto dall’articolo di localseoguide.com:
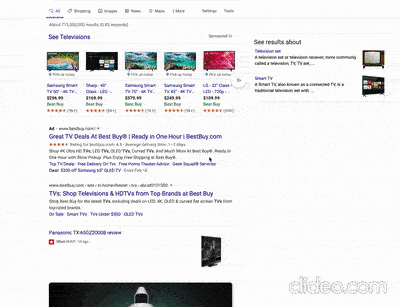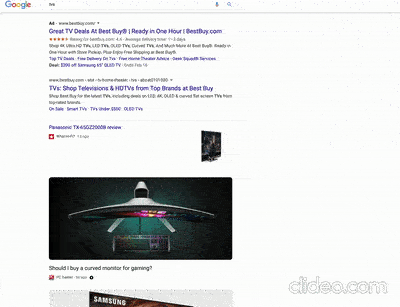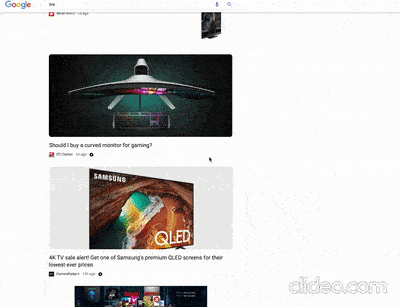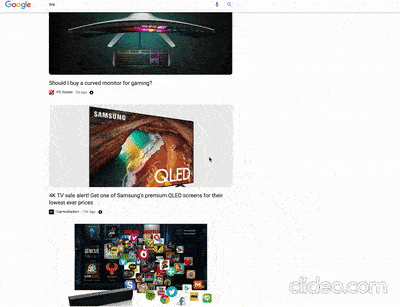
Se queste SERP, che per altro pare siano state già segnalate da SemRush, fossero “confermate” beh, praticamente le SERP relative al mondo ecommerce come le conosciamo non esisterebbero più e il rapporto tra ecommerce e blog cambierebbe radicalmente, anche in termini di business. Devo dire che ci vedo delle opportunità per chi ha visione ed elasticità mentale, non solo dei problemi.
Potrebbe, ad esempio, diventare vantaggioso un modello di business dove dei rapporti più stretti tra uno specifico ecommerce e uno specifico blog vengono regolati attraverso l’adozione di un modello basato su traffico, click o la classica affiliazione, a vantaggio di entrambi i brand (nel caso ci sia un mutuo impegno nell’offrire un servizio di qualità, il nodo rimane questo). Sto parlando di tagliare i mediatori e creare (finalmente) devi veri e propri rapporti sinergici tra attori e, perché no, i brand che rappresentano. Naturalmente si tratta di una soluzione applicabile anche senza che questa nuova tipologia di SERP venga effettivamente implementata. Pensaci su!
Attenzione: questo è solo un test, segnalarvelo per me è un modo di indurti, come ti invitavo qualche parola fa, a pensare e, perché no, a considerare altre azioni/strade nel caso abbiate un e-commerce, un blog o entrambi. Il web è movimento!
Google rilascia un nuovo pannello nella Search Console dedicato alle Review
Segnalato in un tweet di Glenn Gabe, Google ha annunciato sul suo Webmasters Blog di aver inserito nel “performance report” della Search Console una sezione dedicata ai rich results del Review Schema. Non c’è molto da aggiungere!
Google rilascia in licenza open source una tecnologia avanzata di generazione di testo
Lo scorso gennaio Google ha rilasciato una nuova metodologia opensource chiamata LaserTagger, la quale si occupa, per farla molto breve, di modificare (o contribuire a identificare) testi, senza produrre in output una nuova serie di parole ma andando invece a effettuare operazioni sul testo pre-esistente. Questo perché, spesso, nel linguaggio naturale si trovano spesso sovrapposizioni tra output e input. Per intenderci trovi qui di seguito l’esempio di un processo di “fusione di frasi” dato da Google nel suo articolo:
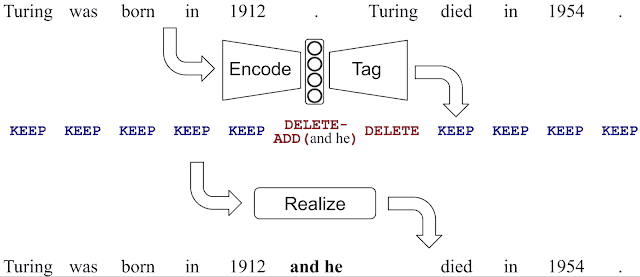
Questa metodologia fa sentire tutta la sua efficienza su larga scala e l’articolo da l’esempio delle “tecnologie di Google che producono linguaggio naturale“: diventa quindi molto interessante anche per chi, con il linguaggio naturale, ci lavora a livello di sviluppo.
Il modello LaserTagger è open-source ed è visionabile/scaricabile su GitHub e puoi trovare un venturebeat.com una presentazione del modello probabilmente migliore della mia.
Il limite del CSS custom di AMP sale a 75kb
Segnalato tramite un tweet da Glenn Gabe, questo articolo su seoroundtable.com riporta che un utente ha scoperto su GitHub che da fine di febbraio 2020 il limite per il CSS custom si alza a 75kb da quello di 50kb in vigore mentre scrivo questa newsletter. Una notizia che probabilmente renderà felici i developer in ascolto!
Approfondimenti SEO della settimana
I “4 comandamenti” di un’implementazione del FAQ Schema
Brodie Clark ha pubblicato sul suo sito alcune nozioni interessanti sul filtraggio del FAQ Schema da parte di Google, le quali per altro non sono pubblicamente dichiarate da Google! Le traduco brevemente per te:
- Possono esserci solo 3 pagine che stampano le FAQ nella stessa SERP: se quindi ti posizioni dopo 3 pagine per le quali Google stampa il FAQ Schema in SERP non potrai avere lo snippet;
- Il FAQ Schema funziona solamente nella prima pagina delle SERP: semplicemente dalla seconda pagina in poi non viene stampato. Se ti posizioni in seconda pagina non riceverai questo snippet;
- Google filtra chi utilizza l’HTML nella domanda del FAQ Schema: seppure è possibile utilizzare l’HTML (e addirittura mettere link, come discusso in questa newsletter) se lo si fa nella domanda, Brodie ad esempio ha utilizzato l’italic (il corsivo), si viene completamente filtrati (e non viene stampato lo snippet in SERP);
- Su mobile il FAQ Schema non viene stampato se è presente un local panel con approfondimenti, per intenderci i pannelli come questo:
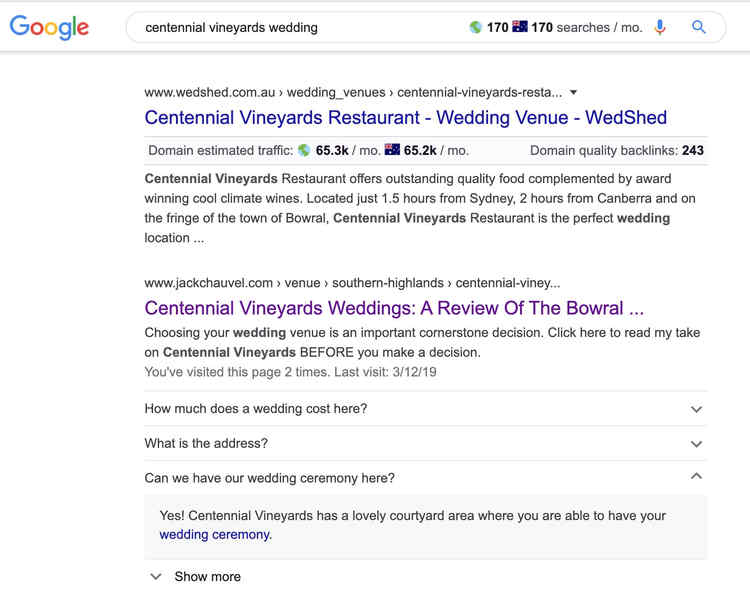
Ora queste cose le sai anche tu!
Bill Slawski ci spiega in modo semplice cosa sia Schema
Sempre a proposito di Schema, con un breve Twitter thread il solito bravissimo Bill Slawski ha spiegato in modo molto chiaro il senso e il significato dell’esistenza di Schema. Probabilmente per te non è qualcosa di nuovo ma visto che potrebbero chiederti appunto perché esista vi traduco le sue parole, potrebbero tornarti utili:
Le vostre pagine web contengono informazioni sotto forma di dati strutturati ed è questo il motivo per i quali i motori di ricerca vogliono Schema: questa implementazione fa da contenitore per i dati, ponendoli in un modello strutturato che rende più facile la comprensione dei contenuti della pagina da parte del motore di ricerca.
Il vocabolario Schema è stato creato da esperti nella materia per contenere dati riguardanti argomenti che sono stati ritenuti importanti per i motori di ricerca e correlati con ciò che le persone potrebbero ricercare utilizzandoli.
Google vuole:
- sapere delle entità che appaiono sulle vostre pagine;
- conoscere le loro relazioni con le altre entità;
- conoscere le loro relazioni con gli attributi (proprietà) delle entità stesse;
- conoscere le relazioni che riguardano le classificazioni, ancora una volta, delle entità;
Quello che è presente nell’implementazione Schema della tua pagina dovrebbe naturalmente anche essere sulla tua pagina (NOTA: intende che se si implementa Schema attraverso puro codice, ad esempio JSON, si deve riportare in modo esplicito gli stessi dati stampati sul frontend per l’utente, ad esempio la proprietà “prezzo” non può essere solo presente nel codice e nascosta all’utente).
Bravo Bill. Una definizione molto utile anche per far capire Schema ai tuoi (nostri) clienti.
John Mueller sulla “lontananza” dalla homepage
Se c’è una cosa che pontifico da tanto tempo è l’importanza della homepage quando si costruisce la struttura di un sito web (prova: questo podcast sulla SEO delle homepage, ancora perfettamente attuale), concetto reiterato da John Mueller durante un Webmaster Central office-hours Hangout e riportato da searchenginejournal.com. Traduco parafrasando:
Quello che succede è che noi (Google) consideriamo l’homepage come una pagina veramente importante e per questo le pagine che ricevono link da essa sono, allo stesso modo, tendenzialmente molto importanti.
Più ci si allontana dalla homepage più penseremo che la pagina che scansioniamo sia meno critica.
Che le pagine che ricevono direttamente link dalla homepage siano importanti è una cosa abbastanza risaputa ma vale la pena ripeterlo: in un sito web ben organizzato le categorie principali e qualsiasi altra pagina importante dovrebbero ricevere link dalla homepage.
(…) Quindi se una news del 2015 è “nascosta” dietro un archivio che è reperibile solo dopo aver trovato l’anno giusto, il mese giusto e quindi la categoria giusta, beh, è un fatto normale.
D’altra parte però se c’è qualcosa alla quale tieni particolarmente, pensi sia veramente importante per il sito, per il tuo business e per i tuoi utenti e la nascondi allo stesso modo noi probabilmente la considereremo come non importante.
Quindi se pensi che una pagina sia importante assicurati che sia facilmente reperibile nella struttura del tuo sito web.
Ci sono considerazioni ulteriori da fare, ad esempio pensare che la homepage è la pagina che tendenzialmente riceve più backlinks in assoluto e che quindi:
- riceve e distribuisce più PageRank;
- funge da punto di partenza per il crawler che “atterra” sul sito attraverso quei link;
Ci sono poi altri ragionamenti da fare, magari fosse così facile… per approfondimenti ti rimando al podcast che ti ho segnalato!
Analisi di un brevetto su come Google potrebbe posizionare i podcast nella sua App dedicata
Il solito mitico Bill Slawski ha scritto un articolo sul suo blog dedicato all’analisi di un brevetto di Google su di un possibile sistema di posizionamento dei podcast nella sua app dedicata.
Devo dire che tra i “fattori” ipoteticamente in ballo ci sono alcune cose sorprendenti e altre meno. Tra le cose che mi “aspettavo”:
- La popolarità del podcast;
- La qualità audio;
- La presenza di “keyword” o comunque di un argomento specifico;
- La presenza di pubblicità;
Tra le sorprese:
- Il fatto che il sistema vada a proporre podcast diversi durante la settimana rispetto a quelli che proporrà nel weekend: una feature molto bella e logica ma che mi ha sorpreso!
- Il fatto che gli episodi “troppo lunghi” possano finire in blacklist quando il podcast più popolare del mondo è quello di Joe Rogan, che per intenderci fattura più di 50mila euro a puntata, è composto da puntate che non durano meno di un’ora e arrivano a più di 3 ore;
- Il fatto che ci sia la “possibilità di apprezzamento” (likelihood of enjoyment) tra i ranking factors quando è sodata la grande flessibilità nel consumo dei podcast tra gli utenti: mi chiedo come farà a stabilire una cosa simile, spero non solo attraverso le interazioni perché mi sembra insensato e non generalizzabile. Non penso che neanche il tempo di ascolto sia una cosa veramente interessante da misurare, vista la possibilità di “dimenticarsi” di avere il podcast o addormentarsi, ad esempio. Sarei molto curioso di sapere come possa funzionare un sistema del genere;
Personalmente questa cosa mi interessa perché… te lo lascio immaginare :).
Tools e guide SEO della settimana
Utilizzare Google Data Studio per controllare che la migrazione HTTPS sia andata a buon fine.
In questo articolo Simon Cox spiega brevemente come utilizzare in modo semplice Google Data studio per fare un rapido controllo del proprio passaggio in HTTPS utilizzando la possibilità di “mischiare” (fare data blending) due fonti di dato in Google Data Studio.
Di fatto si prende come fonte di dati la Search Console della proprietà HTTP, quella della proprietà HTTPS e si procede a visualizzarle nello stesso grafico.
Un’idea semplicissima, utile ma della quale non avevo mai sentito parlare. Per intenderci il risultato può essere questo (le linee sono le impressioni):
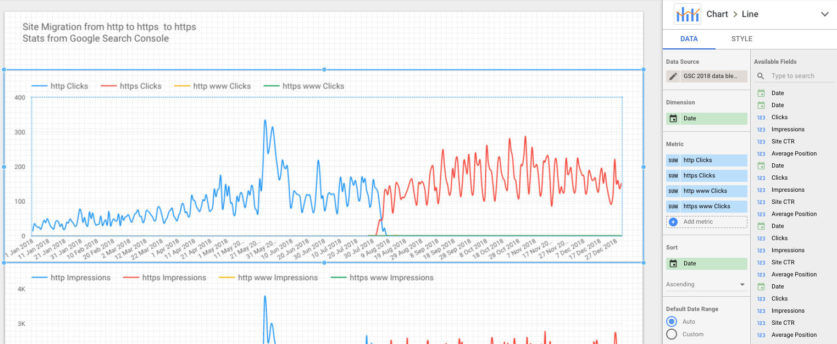
Anche tu hai pensato “come ho fatto a non pensarci prima?“.
L’unico problema è che, se si parla di “debugging” del passaggio ad HTTPS il tempo di attesa per i dati della Search Console sono troppo lunghi: meglio darsi da fare con crawler e web analytics. Quella descritta in questo articolo rimane comunque un buon metodo per capire, nel tempo come si è evoluta la situazione.
Evidenziare le immagini senza alt text via CSS (e una libreria/estensione per il debug dei siti web via CSS)
Sapevate che esiste un selettore, via CSS, per evidenziare le immagini senza tag alt? Io l’ho scoperto attraverso questo tweet di Addy Osmani, il codice è questo:
img:not([alt]) {5px solid red}
Ottimo in caso di analisi e ottimizzazione! Naturalmente il tipo di evidenziamento è totalmente personalizzabile!
Nei commenti degli utenti hanno segnalato la libreria/estensione a11y.css che personalmente non conoscevo, molto interessante per il debugging dei siti web! Io per esempio ho trovato un sacco di problemi su questo sito, rimedierò al più presto!
Un bookmarklet per confrontare side-by-side un sito con e senza il javascript attivo
Non mi sono segnato, purtroppo, chi ha ritwittato questo Tweet di Chris Johnson del settembre scorso ma lo devo ringraziare: il bookmarklet che permette di visionare side-by-side le differenze tra le versioni con e senza Javascript abilitato dello stesso sito è molto interessante e comoda. Per intenderci:
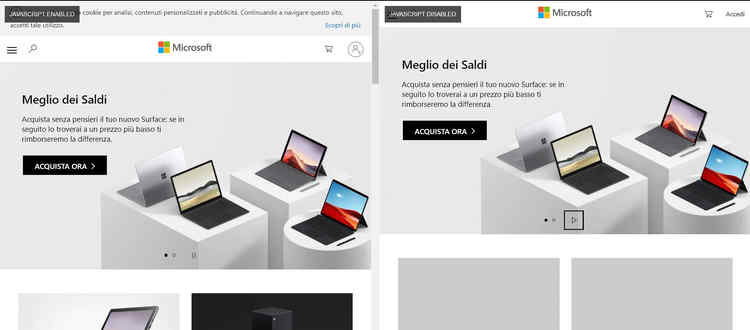
Molto interessante mentre, ad esempio, si analizza un e-commerce e si vuole valutare il “worst case scenario“: le funzionalità saranno attive su device molto vecchie? Cosa succede se Google non riesce a caricare le librerie necessarie per stampare la pagina? Un ottimo tool!
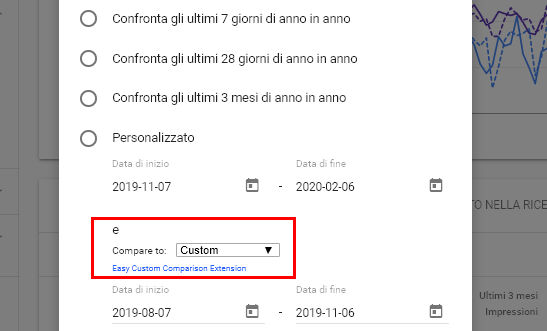
Un’estensione di Chrome per comparare dei periodi in Search Console
Dan Shure ha segnalato su Twitter una cosa molto interessante, ovvero questa estensione di Joe Hennessey che permette, dove è possibile confrontare per data, confrontare velocemente i dati di Search Console con il “periodo precedente”, a la Google Analytics per intenderci (senza questa estensione bisogna fare a mano). Aspettando che Google si svegli e che implementi questa semplice funziona la soluzione di Hennessey è molto comoda. Bravo!
Un generatore di FAQ Page Schema via JSON-LD by Saijo George
A parte l’epicità del nome da manga del suo creatore questo generatore di codice per il FAQ Schema in JSON-LD di Saijo George è un bel tool, realizzato con grande cura e potenzialmente molto utile, magari utilizzato insieme alla strategia di Lily Ray che ho citato qualche newsletter fa di inserire un link dentro lo snippet. Tra le funzioni la possibilità di:
- Creare in modo molto “grafico” lo snippet, ottimo per chi è meno tecnico;
- Con un pulsante testarne il codice nello “structured data testing tool” di Google;
- Trasformare il codice in una versione “compatibile” con il deploy via Tag Manager (pare che ci siano incompatibilità con il codice “liscio”, non lo sapevo);
Per altro scopro dallo “how to“del tool che Google stampa nel rich result anche gli headings e i line break, non lo sapevo proprio! Bravo signor Saijo (che nome pazzesco)!
PS: salvatevi questi tool perché “il markup Schema non diventerà più semplice nel prossimo futuro“, parola di John Mueller.
Una raccolta di Regex e XPaths per la SEO
Davvero molto comoda questa raccolta di Regex e XPaths utili per la SEO di Tobias Willmann, praticamente un nuovo segnalibro obbligato nel browser del tuo computer di lavoro!
Detto questo nell’informatica è inutile re-inventare ciò che è già stato inventato, meglio migliorarlo! Proprio per questo non abbandonerò il progetto di farne una lista ancora più completa, in questa ne mancano alcune…!
Approfondimenti dal web
Evidenziare il testo di una pagina attraverso un link su Chrome
Segnalata da questo tweet di Stefan Jusid ho scoperto che in Chromium verrà implementata la possibilità, tramite URL, di avere una versione della pagina d’atterraggio con una stringa evidenziata e lo scroll automatico verso di essa, senza bisogno degli ID dei div come per il sistema delle ancora interne alla pagina (quelle con il cancelletto usate, ad esempio, nella table of contents di questa pagina).
La feature sarà attiva di default nella versione 80 di Chrome, in rilascio proprio in questi giorni. Chissà se vedremo i log invasi da questo tipo di URL con Googlebot che, seguendo qualche link in giro per la rete, pensa che siano link interessanti da navigare…
Google rilascia un framework di un AI che adatta le inquadrature video in diversi formati
Il 13 febbraio Google ha rilasciato AutoFlip, un framework che permette il crop automatico (il cambio di inquadrature) tramite AI in diversi formati video. Per intenderci:

Dei teenager stanno usando Instagram come un “sostituto” di eBay
…trasformare Instagram in un ebay per teenager: come raccontato in questo articolo di inputmag.com alcuni ragazze molto giovani stanno usando Instagram come una vera e propria casa d’aste dove rivendere i vestiti comprati nei negozi dell’usato ad altri coetanei, con un’esperienza utente “rustica” ma evidentemente efficace. Per intenderci ecco la “homepage” di uno di questi profili:
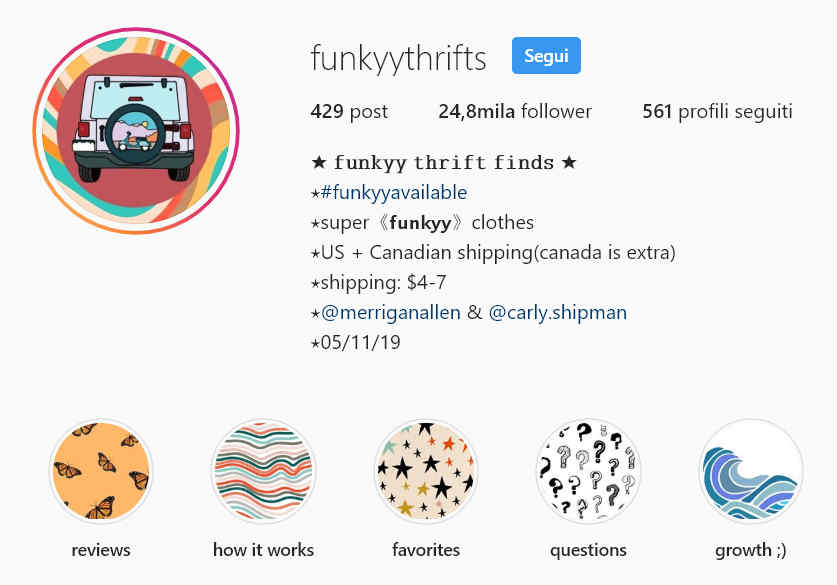
Le CTA per le raccolte di stories sono utilizzate come un vero e proprio menu di navigazione e le stories stesse spiegano molto velocemente il servizio e i termini di vendita: molto creativo, chiaro ed efficace, mi sa che abbiamo da imparare da queste ragazze.
Per quel che mi riguarda è sempre affascinante vedere come individui con sensibilità diverse possano prendere sistemi relativamente semplici come Instagram e inventare di sana pianta “usi impropri” ma evidentemente desiderabili dall’utenza, senza pubblicità, fanfare o altre amenità: fa riflettere!
La versione filippina di Wikipedia è stata scritta nella sua quasi totalità da un bot
Sono rimasto molto sorpreso da due cose dichiarate da questo articolo di Vice:
- la versione in cebuano (la lingua delle Filippine) di Wikipedia è la seconda più grande al mondo;
- la versione in cebuano di Wikipedia è mantenuta da soli 20 utenti (contro i quasi 140mila di quella inglese, l’unica più grande) in quanto è stata creata nella sua quasi totalità, 5.331.028 articoli sul totale di 5.378.570, più del 99%, da un bot creato del fisico svedese Sverker Johansson chiamato Lsjbot;
A quanto pare ci sono diversi fronti riguardo l’utilizzo massivo di bot per la creazione di materiale, di fatto, enciclopedico, sia a livello tecnologico (la tecnologia è ancora acerba) ed etico (è giusto lasciare in mano all’automatismo una fonte piuttosto attinta di conoscenza?). Un argomento molto affascinante.
Mozilla licenzia 70 dipendenti per far fronte ai “tempi duri” (e alla sua dipendenza da Google)
Personalmente non sapevo il revenue di Mozilla dipendesse al 90% da… Google! Con un certo grado di “conflitto di interessi“, se così si può definire, rispetto alla sua mission di migliorare di un Internet aperta, pubblica e accessibile, viene infatti pagata da Google per far si che esso rimanga il motore di ricerca di default di Firefox e Google, noi lo sappiamo bene, non abbraccia esattamente gli stessi ideali, anzi.
Detto ciò quello che l’azienda vorrebbe fare, si legge dall’articolo, è trovare nuove fonti di revenue attraverso servizi e prodotti basati sul modello delle subscription, tra i quali la VPN di Firefox, Firefox Private Network, per ora disponibile solo negli Stati Uniti al prezzo di $4,99 dollari al mese. A dire la verità avrebbe voluto farlo anche nel 2019 ma gli è andata male.
Ci aspettavamo di avere, nel 2019 e nel 2020, del revenue dai nuovi prodotti in formato subscription e un revenue più alto da fonti che non fossero la ricerca. Purtroppo ciò non è accaduto. Il nostro piano del 2019 ha sottostimato quanto tempo avremmo impiegato a costruire e distribuire dei nuovi prodotti in grado di generare questo revenue.
Anche i grandi possono sbagliare le loro valutazioni, il problema è che come dice il detto “più sono grandi più faranno rumore cadendo“: ora che dal 15 gennaio 2020 Microsoft Edge è basato su Chromium un prodotto come Firefox deve rimanere sano per avere un mercato sano.
Che faresti tu se fossi il CEO di Mozilla? Io qualche idea, da umile SEO, ce l’ho: penserei ad una integrazione più verticale con alcune piattaforme online, magari dando feature esclusive su servizi per i giovani, bombardati di pubblicità di VPN sui contenuti gaming, come Twitch, Tik Tok e Instagram. Purtroppo però non penso che un’idea come questa sia compatibile con la già citata mission dell’azienda. Sarò curioso di osservare le prossime mosse.
Il pensiero della settimana
La settimana scorsa ho fatto il “soft launch” del progetto EV Patreon accorgendomi che, preso dall’entusiasmo, non ho tarato proprio benissimo la comunicazione e l’organizzazione del tutto, ho voluto quindi aggiustare il tiro! Per intenderci:
- Ho cercato di rendere più chiaro quello che puoi ottenere dal progetto: materiale SEO esclusivo (case history, guide, tool) che non trovi da nessun’altra parte, perché tratta della SEO vera e propria che faccio per me e i miei clienti. Non ci sono molti colleghi al mondo che hanno messo a disposizione dati del genere. Personalmente non ho paura di “crearmi concorrenti”, credo davvero nella condivisione;
- Ho introdotto un prezzo promozionale per i primi 30 iscritti (29, visto che mentre scrivo queste ore do il benvenuto al primo iscritto post beta-test). Se già la membership “normale” penso sia un ottimo investimento, visto la quantità e il tipo di materiale che si ottiene nel giro di 12 mesi (che non si trova in un corso in aula di 2 giorni che si pagherebbe molto di più), al prezzo promo, bloccato per sempre, è davvero un’ottima occasione per migliorare la propria SEO!
- Ho aumentato il numero di contenuti per i nuovi iscritti, che passano da quelli del singolo mese in corso a quelli degli ultimi 3 mesi più tutti gli “extra” che pubblico ogni mese. Questo perché non ho paura del “prendi e scappa“: una volta “dentro” ti renderesti conto della qualità dell’offerta e non penso scapperesti via il mese dopo :);
Insomma io ti aspetto! E a proposito voglio ringraziare nuovamente chi supporta attivamente questa newsletter, ovvero i membri attuali di EV Patreon. E quindi grazie a:
- Carlo
- Cristina
- Elia
- Fabrizio
- Gianni
- Giovanni
- Luca
- Marcello
- Maurizio
- Roberto
- Salvatore
- Simone
Infine voglio ringraziare anche te per avermi dedicato il tuo tempo leggendo fino a qui! Se è la prima volta che leggi questa newsletter e non vuoi perderti la prossima, se vuoi leggere le precedenti o più semplicemente vuoi dire la tua su quanto è stato detto non devi fare altro che scrollare ancora un pochino:
Grazie nuovamente per aver letto fin qui e ti auguro un buon proseguimento!
Hi Emanuele
Thanks for mentioning my FAQ schema generator in your newsletter
Hello George! Thank you for your great tool and your kind comment, i’m looking forward to share many more great content from you 🙂
Thanks man
Top come sempre.
Grazie Giandomenico!